
from-optimization-to-ml
From Optimization To Machine Learning
ps:数学公式好多渲染出奇怪的问题,我佛了,看看换个渲染引擎
Regession Problems
General
先补充回顾一下范数
我们前面包括后面见到的 就是 l2 范数,表示向量或者矩阵的元素的平方和:
- 回归方法是建立模型常用的一种策略,当我们有数据但没有建立起具体的模型或者是想要一个便于计算的模型时,回归模型是一种不错的选择。它可以从多个预测变量中得到一个连续的预测值。
我们假设有 M 个输入的点 ,对应输出
,构成二元对
,我们的目标是训练一个函数
。
- 虽然插值(interpolant)可以很好和精巧的找到这样的 f,但实际现实中的数据往往包含噪声,对于这样的点,插值模型会很大程度上受到数据的影响,模型的普适性很差。更好的方法是用 N 个基础函数去表示 f:
系数 可以告诉我们对应的函数(可以理解为函数提取出来的特征)在预测数值时的重要性。
是我们认为设置的,我们要训练的就是系数
,老方法,把它转换为一个优化问题:
写成矩阵的形式:
这样,我们就可以将原来的优化问题化为标准形式:
线性回归的优化问题可以用解方程来解决,避免了迭代方法:
实际上,对于监督学习的神经网络就是非线性的回归模型。
Regularization
线性回归(Linear regression)指回归模型的系数是线性的,模型的输入并没有必要是线性的。对于线性最小二乘问题,我们可以直接求出最小值点,对于一些有高维度系数的问题,有特殊的数值方法去寻找解。
- 当数据点的个数比要学习的参数多时,方程的个数大于未知数的个数(M > N),最小二乘问题是**系统超定(overdetermined)**的,反之是未确定的(underdetermined)。
- 对于超定的最小二乘问题通常有特殊解,而未确定系统有无穷多个系数可以使损失函数最小,虽然他们得到的目标函数的值是一样的,但在预测未知点的时候有很大的不同,这个问题被称为不适定问题(ill-posed problem)
- 要解决不适定问题,一种方法是平衡要估计的参数和数据点个数,另一种方法是正则化(regularization),正则化在原目标函数上增加了惩罚项:
是正则化系数,$ R ( c ) $ 是正则化项。$ R ( c ) $ 有很多种选择,比如:
- L2 正则化:Tikhonov regularization (Ridge regression) $ R( c )={||c||}_{2}^{2} = { \sum_n^{N} c_n^2} $
- L1 正则化:LASSO (sparse regression) $ R ( c )= ||c|| _1= \sum_n^N \left | c_n \right | $
为什么增加惩罚函数会有效?
- 当你的参数比数据点还多的时候,你会希望一些参数的值为 0,而我们以 L1 形式为例,它就有这样的魔法,让一些不是很重要的参数变成 0。结合下面的图,我们给出从图像角度的理解:
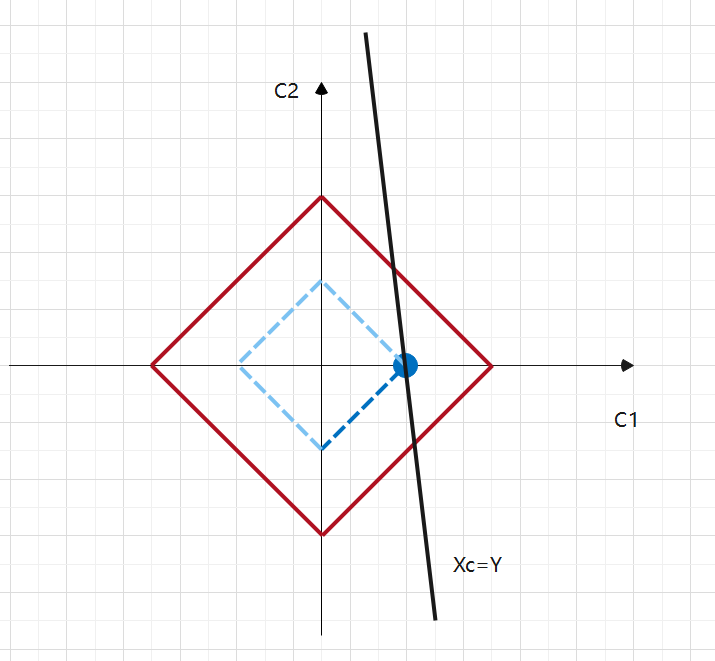
我们绘制出 L1 惩罚函数的图像,横坐标和纵坐标是 c1 和 c2 满足 ,他们的曲线构成了一圈一圈的正方形。接着我们画出
达成最小值的解 c1 和 c2 的图像,有很多的点,他们构成一条直线,直线必然与
有个交点,这取决于 k 值,但要确保我们的目标函数为极小值,我们也要让 k 尽量的小,也就是尽量靠内侧的正方形,在图中表现就是交点,同样也是与 c1 轴的交点,此时 c1 = k, c2 = 0
就选择了最重要的系数 c1。
Python 中的线性回归
1 | # Create linear regression object |
Classification Problems
- 分类问题是针对于离散的点或者不连续的输出的方法,用线性回归模型去建立分类器可能并不好,回归模型不会被限制为具有离散的输出,并且可以在范围外进行预测。
Logistic Regression
逻辑回归将线性模型转变为逻辑函数的形式$logistic(s) = \frac{e^{s} } {1+e^s } $:
其中 表示模型中的参数
。逻辑函数的特征是:输出范围为
,对于小的输入,输出接近 0;对于大的输入,输出接近 1。
这样我们要解决的优化问题如下:
代表所有输入是
,输出
的点。目标函数力图让
时我们函数的预测值尽可能的接近 1,当
时尽可能预测值为 0,这样
最大。在统计学中,常常使用极大似然估计法来求解,即找到一组参数,使得在这组参数下,我们的数据的似然度(概率)最大。为了方便求解,我们通常求对数:
- 逻辑回归不仅可以做二分类问题,不仅可以预测出来类别,还能得到预测的概率,在逻辑回归模型中,我们最大化似然函数和最小化损失函数实际上是等价的。
Multi-valued logistic regression
例子:待完成
Stochastic Gradient Descent
回归,分类问题,参数估计都需要解优化问题,它们有一个一般的形式:
l 是损失函数,表示预测值和实际值的误差,而在每个数据点误差的和常常被称为经验风险(empirical risk)。对于回归问题, 是平方误差
,对于逻辑回归,
。
当我们的数据集很大的时候,迭代方法每次都要对所有的点计算 M 大小的梯度值就会导致很耗时,随机(stochastic)梯度下降(SGD)通过随机选择一个数据集的子集去计算梯度,并用这个值来近似整体的梯度,一个简单的方法就是每次迭代选择一个点:
- 随机从
选择 j 点
- 用这个点计算每一步梯度的值:
通过每个样本都重复迭代,如果数据有1万条,就迭代1万次,每次用一个点计算来获取最优解,而梯度下降迭代一次要用到全部的样本。优点当然是训练的速度快,缺点是噪声较多,每次迭代不一定朝着整体最优化的方向前进。
Mini-Batch Gradient Descent
在权衡随机梯度下降和批量梯度下降方法后,便有了小批量梯度下降法(MBGD),每次迭代的时候用样本的子集,样本的一部分来代替全部的样本计算梯度。比如说有 1000 个样本,我们选择 10 个一组,这样就有了100 个 mini-batch,重复 100 次计算,每次有 $ c_{n+1}=c_n- \frac{1}{10} \alpha \nabla_c \ell(y_j, f(x_j;c_n)); j=1…100; x_j = [x_j^1, …, x_j^{10}]$
Assessing Model Fit
- 当我们训练的模型对于训练集的一些不重要的特征关注的太多了后,在新的数据到来时表现的结果很差,这就是过拟合(Over-fitting),我们需要一种验证误差的方法,它可以帮助我们决定什么时候停止训练来避免过拟合。
对于回归模型,很经典的方法是计算确定系数
表示输出的 y 值的平均值,
越接近 1 说明模型很好的表现了数据的变化,如果数据集有很多的噪声,可能会导致
很小,但有可能模型依旧有很好的适应性和预测能力
from-optimization-to-ml
http://cyx0706.github.io/2021/03/11/from-optimization-to-ml/