
aix
2021/3/9 补充了数学层面的牛顿公式理解和在求解最小二乘问题中的应用
Optimization
一个优化问题包含三个部分:
- 优化的参数
- 损失函数
- 约束(可选)
优化问题实际上就是寻找参数来使得在约束的范围内损失函数最小。
LEAST SQUARES PROBLEMS
最小二乘问题是很经典的优化问题。
考虑这样一个线性方程组:
我们将解一个线性方程组变化为一个无约束的最小值问题:
这就是一个线性的最小二乘问题。虽然线性方程组仅在某些条件下具有解决方案,如条件不能约束过度,但最小值问题在过度约束下依旧是有解的,并且可以直接计算等式来获得:
我们通常记 Moore-Penrose 逆矩阵,也通常将其简记为
(M dagger 还真就是匕首)
Gradient Descent
迭代方法包括 3 个主要部分:
- 解的初始猜想
- 每一步的迭代方法
- 收敛的标准
梯度下降是一种求最优解的迭代方法,它设置了初始猜想值为,每一步都向下降最快的方向前进一步(负梯度),当当前的 x 的梯度为 0 或者接近 0 时,算法停止。
- 初始值
,假设初始最优解为
- 更新 x:
- if $\left |\nabla J(x_{k+1}) \right | < \tau $ 停止,
为最优解,否则令
,重复第二步。
其中,是损失函数,
是它的梯度,一般来说,梯度可以定义为一个函数的全部偏导数构成的向量(这一点与偏导数与方向导数不同,两者都为标量)。
是步长,
是一个定义的允许的误差值。
- 梯度下降得到的是局部最优解,一个局部最小值(local minimum),而不一定是全局的最小值(global minimum)
- 梯度下降的性能和表现取决于它的步长,如果步长太大,会导致无法收敛;而小的步长会增加迭代的次数,增加开销。
- 梯度下降需要我们能够写出来损失函数和计算损失函数的梯度,有的时候我们无法找到一个合适的损失函数去评估或者无法计算其梯度。
Newton’s Method
概念
牛顿法同样也是一种迭代方法。它和梯度下降很相似。即我们在寻找的时候采用 Newton-Raphson 寻根法。
- 初始值
- 更新 x:
- if $\left |\nabla J(x_{k+1}) \right | < \tau $ 停止,
其中,是 海森矩阵(Hessian Matrix),是一个多元函数的二阶偏导数构成的方阵,描述了函数的局部曲率。
用公式来描写的话就像下面这样:
- 牛顿方法是一个二阶方法,它的每次计算都要计算二阶偏导。
- 同样由于是迭代法,依旧只能找到局部最优解,也同样很依赖
的选择。但总体来看,牛顿方法可以用更少次数的迭代就使得结果收敛,但每一步的计算量很大。
- 沿用牛顿的方法的思路,有另外一种优化算法被称作拟牛顿法(Quasi-Newton Method),但这些方法采用梯度信息来近似海森矩阵,所以比传统的牛顿法更加有效。
数学层面理解
牛顿公式:
若要求原函数的极小值,即在上寻找根,这样就可以应用牛顿方法:
在高维空间,将一阶导换成梯度,二阶导换成海森矩阵就得到了前面的式子。
例子:两者的比较
1 | # 博客优化问题部分对应的例子: 梯度下降法和牛顿方法的比较 |
在没有步长衰减的情况下,得到的图像如下:
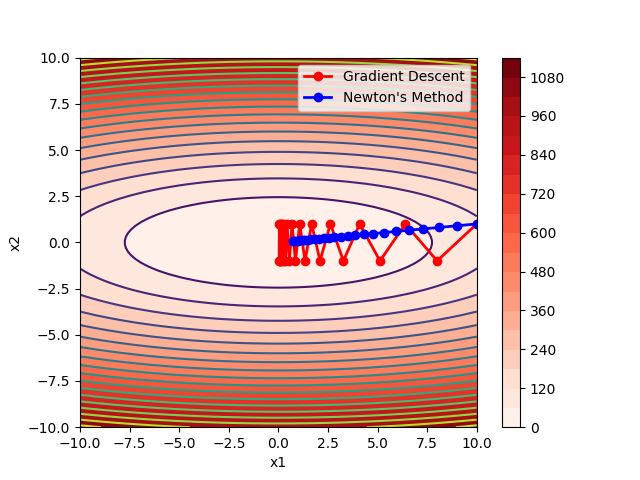
牛顿法显然更好,完全避免了左右横跳,因为牛顿法能看的更远,牛顿法有函数的二阶导数的信息,不仅知道哪一点可以下降的最快,而且还知道从这个点走一步后得到的下一个点的梯度的大小。这就解释了为什么牛顿法会避免"之"字形,因为之字形当前的梯度虽然比较大,但是下一步的梯度不大,而如果顺着"山脊"走,可能当前的梯度没有"之字形"的梯度大,但是下一步可能的梯度会更大一点。
如果加入步长衰减,适当增加最大步数,得到结果如下:
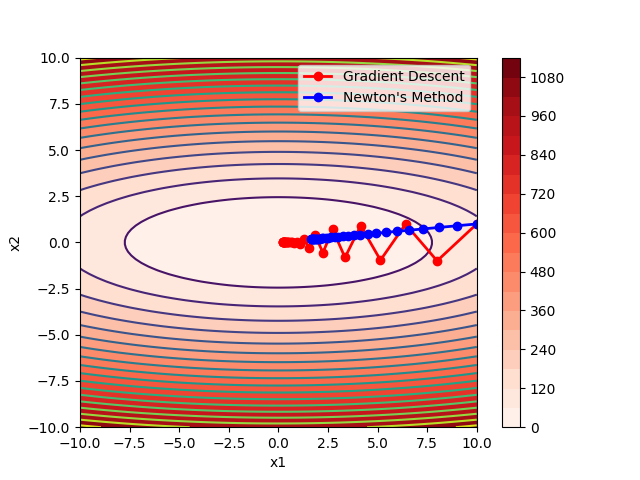
明显的梯度下降方法准确度上升很多,不再是在最小值点左右横跳无法收敛了。但相比之下对牛顿方法没有太大的影响。
Nonlinear Least Squares
概念
假设我们有模型 f,输入 z 和 x 参数。,这样一个模型既可以是一个线性函数,也可以是一个非线性函数:
- 如:f 是多项式函数,x 是 f 的系数。
- 如:z 是初始时刻在一个导热棒上温度的分布情况,y 是最终最大温度值。f 涉及模拟热传导方程来计算 y 值,x 可以被定义为在这个物体上的热扩散率。
我们要对这个函数做参数的优化,为了找到最好的最适合当前数据集的 x,我们先收集在 m 个输入下的 m 个点 , 用这些点去寻找最优的 x
对于这个优化问题,损失函数怎么定义?对于每个函数,我们考察预测值和实际值的误差:,把所有的误差相加得到我们的误差函数(也就是优化的目标函数)
这个问题被称为非线性最小二乘问题,由于目标函数是一个非线性函数。解这个问题当然还是可以使用迭代方法,相当于求解如下优化问题:
这个函数也被称为经验风险最小化函数。对于梯度下降方法,我们假设初始值是 x_0,步长为 ,根据我们前面学的迭代公式:
上面目标函数的梯度公式为:
其中 是 f 在 x 方向上的梯度:
为什么我们不直接对原函数采用梯度下降等方法来寻找最小值? 因为 并不能确保我们找到了局部最小值,梯度为0既可能是最小值,也有可能是最大值,我们无法根据一阶倒数或者偏导来确定。
Applied in Least-Squares?
Gradient Descent
如果采用梯度下降方法去优化最小二乘问题的目标函数:
代入梯度下降公式,得到的递推式如下:
Newton’s Method
如果采用牛顿方法,令
我们前面知道,最小二乘问题的最优解为
又计算得出 ,
,代入上式可得:
一步到位直接求得极值点。这是从数学推导角度来看的,如果从二阶导方面来理解,牛顿方法包含二阶倒数的近似值来进行迭代计算,而最小二乘问题的目标函数一个二阶的,所以精确的用一步可以找到解。