软件工程炼丹心得与体会
其实就是深度学习入门吧
大三上软工项目:鸟类识别与分享平台,项目传送门iBird
在充分了解了深度学习(指前两周看了老师发的视频)后开始尝试构建鸟类识别模型,这篇博客用于记录自己在学习中的一点点收获。
ps:基础太差了,感觉好多时候都是在瞎炼。
一点点准备
模型的构建
细粒度图像识别
200 种鸟类识别其实是一个细粒度图像识别问题(fine-grained image recognition)
对于现在的模型,识别出物体的大类别(比如:猫,狗,手机,车)比较容易,但如果要进一步去更细的划分物体的类别和名称,难度就大了很多,在这其中,有一些子类别的差异十分的小,如何区分布他们是比较困难的。
目前,精细化分类的方法主要有以下两类:
基于图像重要区域定位的方法:该方法集中探讨如何利用弱监督的信息自动找到图像中有判别力的区域,从而达到精细化分类的目的。
基于图像精细化特征表达的方法:该方法提出使用高维度的图像特征(如:bilinear vector)对图像信息进行高阶编码,以达到准确分类的目的。
举我看的论文里面的例子吧:
在 Bilinear CNN Models for Fine-grained Visual Recognition 这篇论文里提到了:
Fine-grained recognition tasks such as identifying the species of a bird … are quite challenging because the visual differences between the categories are small and can be easily overwhelmed by those caused by factors such as pose, viewpoint, or location of the object in the image.
这里提到了,细粒度识别的一个很大的难度在于"细小的差别会被鸟的姿势,视角,拍摄的位置给掩盖掉"(这里是以鸟为例)
For example, the inter-category variation(类别间的变化) between “Ringed-beak gull” and a “California gull” due to the differences in the pattern on their beaks(喙) is significantly smaller than the inter-category variation on a popular fine-grained recognition dataset for birds.
论文中举了环嘴鸥(Ringed-beak gull)和加州鸥(California gull)在喙上的差别要明显小于细粒度分别的数据集中的差别。
为了解决这个问题,这篇论文中提出了一个 BCNN 模型来解决,我主要学习的也是这个模型,不过这是后面要说的了。
预处理
在正式写我们的模型前,要先写好读取数据的方法,数据集就用 AI 研习社上的了,先在本地下一份。
对于数据,我们交给模型训练的时候,一般都会进行预处理,预处理的方法有很多,最常用的如下:
平移:一定尺度内平移
旋转:一定角度内旋转
翻转:水平或者上下翻转
裁剪:在原有图像上裁剪一部分
颜色变化:rgb 颜色空间进行一些变换(亮度对比度等)
噪声扰动:给图像加入一些人工生产的噪声
说的高级点好像叫数据增强
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 from torchvision import transforms as transformstransforms.Resize((100 , 200 )) transforms.RandomCrop(100 ) transforms.CenterCrop(100 ) transforms.RandomVerticalFlip(p=1 ) transforms.RandomHorizontalFlip(p=1 ) transforms.RandomRotation(45 ) transforms.ColorJitter(brightness=1 ) transforms.ColorJitter(contrast=1 ) transforms.ColorJitter(saturation=0.5 ) transforms.ColorJitter(hue=0.5 )
数据集
Pytorch 提供内置的图片数据集 ImageFolder,它有一个通用的数据加载器,它加载的数据要求以下面的方式组织:
1 2 3 4 5 6 7 8 9 base_dir = "xxx/xxx" predict_sets = torchvision.datasets.ImageFolder(os.path.join(base_dir, "data_dir" ), transform=your_trans)
这时读入的数据所有在 dog 文件夹下的都被打上了 dog 的标签,同理 cat。简单来说,你要将一类的图片全部放入一个以这个类别命名的文件夹下才能正常的读取。
这对于我们这个显然不太方面,所以就要自己写数据集的加载方式了
All datasets are subclasses of torch.utils.data.Dataset i.e, they have __getitem__ and __len__ methods implemented. Hence, they can all be passed to a torch. utils.data.DataLoader which can load multiple samples parallelly using torch.multiprocessing workers.
就是要我们实现两个函数__getitem__() 和 __len__()
1 2 3 4 5 6 7 8 9 10 11 12 13 class FirstDataset (data.Dataset ): def __init__ (self ): pass def __getitem__ (self, index ): pass def __len__ (self ): pass
有了这个我们思路就很清晰了,由于我们的标签都在一个 .csv 文件中,里面包括图片名对应的标签号,我们用 Pandas 读入然后分列,在我们的__getitem__() 函数里一次取一个就好了(取第 item 个)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 import osimport pandas as pdimport torchfrom torchvision.datasets.folder import accimage_loader, pil_loaderdef default_loader (path ): from torchvision import get_image_backend if get_image_backend() == 'accimage' : return accimage_loader(path) else : return pil_loader(path) class CustomDataset (torch.utils.data.Dataset ): def __init__ (self, data_path, data_label_path, data_transform, data_loader=default_loader ): """ :param data_path: 要读取的文件的路径 :param data_label_path: 标签数据的路径 :param data_transform: 数据变换模式 :param data_loader: 加载方法 """ df = pd.read_csv(data_label_path, header=None ) self.data_loader = data_loader self.data_transform = data_transform self.data_path = data_path self.img_names = list (df[0 ]) self.labels = list (df[1 ]) def __len__ (self ): return len (self.img_names) def __getitem__ (self, item ): img_name = self.img_names[item] img_path = os.path.join(self.data_path, img_name) label = self.labels[item] img = self.data_loader(img_path) try : img = self.data_transform(img) return img, label-1 except : raise Exception("cannot transform image: {}" .format (img_name))
训练函数
Tranier 的写法比较固定,网上有各种各样的,贴一个我找到~~(自己写不来,但改了一下)~~
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 from typing import Tuple import torchfrom torch.nn import Modulefrom torch.optim.optimizer import Optimizerfrom torch.utils.data import DataLoaderfrom tqdm import tqdmfrom torch.optim.lr_scheduler import ReduceLROnPlateauclass Trainer (object def __init__ ( self, model: Module, criterion: Module, optimizer: Optimizer, device: torch.device ) -> None : super (Trainer, self).__init__() self.model: Module = model self.criterion: Module = criterion self.optimizer: Optimizer = optimizer self.device: torch.device = device def train (self, loader: DataLoader ) -> Tuple [float , float ]: total_loss, total_acc = 0.0 , 0.0 self.model.train() try : with tqdm(enumerate (loader), total=len (loader), desc='Training' ) as proc: for _, (inputs, targets) in proc: inputs = inputs.to(self.device) targets = targets.to(self.device) outputs = self.model(inputs) loss = self.criterion(outputs, targets) self.optimizer.zero_grad() loss.backward() self.optimizer.step() _, predicted = torch.max (outputs, 1 ) total_loss += loss.item() total_acc += (predicted == targets).float ().sum ().item() / targets.numel() except Exception as e: print ("Running Error in training, " , e) proc.close() return -1 , -1 proc.close() return total_loss / len (loader), 100.0 * total_acc / len (loader) def test (self, loader: DataLoader ) -> Tuple [float , float ]: with torch.no_grad(): total_loss, total_acc = 0.0 , 0.0 self.model.eval () try : with tqdm(enumerate (loader), total=len (loader), desc='Testing ' ) as proc: for _, (inputs, targets) in proc: inputs = inputs.to(self.device) targets = targets.to(self.device) outputs = self.model(inputs) loss = self.criterion(outputs, targets) _, predicted = torch.max (outputs, 1 ) total_loss += loss.item() total_acc += (predicted == targets).float ().sum ().item() / targets.numel() except Exception as e: proc.close() print ("Running Error in validating," , e) return -1 , -1 proc.close() return total_loss / len (loader), 100.0 * total_acc / len (loader)
比较喜欢这个写法,tqdm 是一个 Python 的进度条库,它有个问题是如果代码异常结束,它有时不会被停止,这样在第二次运行时会无法刷新输出窗口,导致看上去就不是一个进度条了,而是进度条每更新一次就打印出来一个新的,原来的还在。我们在套一个 try-catch 在异常的时候正确的关闭这个进度条进程就好了,用 close() 函数。
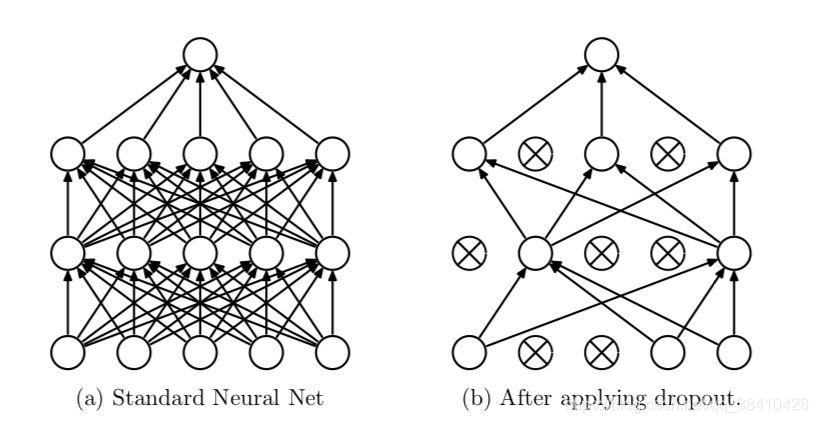
model.eval() 和 model.train()这两个必须要搞明白
model.train() 会启用 BatchNormalization 和 Dropout 而 model.eval() 不启用 BatchNormalization 和 Dropout。
否则的话,有输入数据,即使不训练,它也会改变权值。这是 model 中含有 batch normalization 层和 dropout所带来的的性质。
想象一下,如果被删除的神经元是唯一促成正确结果的神经元。一旦我们不激活它,其他神经元就需要学习如何在没有这些神经元的情况下保持准确。这种 dropout 提高了最终测试的性能。但它对训练期间的性能产生了负面影响,因为网络是不全的。
数据集加载
用 torch.utils.data.DataLoader 就可以,需要注意的是 Windows 下需要将 num_workers 设置为 0。
dataloader 一次性创建 num_worker 个 worker,他们负责将数据提前读入好内存。num_worker 设置得大,好处是寻 batch 速度快,因为下一轮迭代的 batch 很可能在前面几轮的迭代时已经加载好了。坏处是内存开销大,也加重了 CPU 的负担。num_workers 的经验设置看自己的 CPU 和 RAM 吧,如果 CPU 处理强,内存大,就可以设置得更大些。如果 num_worker 设为 0,意味着每一轮迭代时,dataloader 不再有自主加载数据到 RAM 这一步骤(没有worker了),而是在RAM 中找 batch,找不到时再加载相应的 batch。这样当然是速度慢。
模型
我鸟类识别的模型实现了两个(还有一个出问题了先不管他 )
BCNN
Bilinear CNN Models for Fine-grained Visual Recognition
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 class BilinearModel (nn.Module ): """Load model with pretrained weights and initialise new layers.""" def __init__ (self, num_classes: int = 200 , pretrained=True ) -> None : """Load pretrained model, set new layers with specified number of layers.""" super (BilinearModel, self).__init__() model: nn.Module = models.vgg16(pretrained) self.features: nn.Module = nn.Sequential(*list (model.features)[:-1 ]) self.classifier: nn.Module = nn.Linear(512 ** 2 , num_classes) self.dropout: nn.Module = nn.Dropout(0.5 ) nn.init.kaiming_normal_(self.classifier.weight.data) if self.classifier.bias is not None : nn.init.constant_(self.classifier.bias.data, val=0 ) @overrides def forward (self, inputs: torch.Tensor ) -> torch.Tensor: outputs: torch.Tensor = self.features(inputs) outputs = outputs.view(-1 , 512 , 28 ** 2 ) outputs = self.dropout(outputs) outputs = torch.bmm(outputs, outputs.permute(0 , 2 , 1 )) outputs = torch.div(outputs, 28 ** 2 ) outputs = outputs.view(-1 , 512 ** 2 ) outputs = torch.sign(outputs) * torch.sqrt(outputs + 1e-5 ) outputs = nn.functional.normalize(outputs, p=2 , dim=1 ) outputs = self.dropout(outputs) outputs = self.classifier(outputs) return outputs
论文中原本推荐使用两个不同的模型来提取特征值然后使用一个双线性函数来进一步处理提取的特征值,后来又有人指出,使用同源的模型也可以得到不错的效果,所以我就尝试使用了 VGG 作为提取层,然后将处理好的结果使用一个全连接层对应 200 种鸟类。最后正确率在 75% 左右。
EfficientNet With Attention
Attention机制还没咋看的(有空再补了),看别人这么用我也就瞎几把组合了一下。
Pytorch 实现的 EfficientNet
论文在此
这个我看懂了(震声!),论文对现有模型提出了反思:如果只是增加模型的深度(有多少层)(depth),宽度(每一层的参数数)(width),还有图像的解析度(输入的大小)(resolution)其中之一对模型的提升不完全而且有时还会导致准确率下降。Google 的研究员们发现当按照一个比率(ratio)同时提升这 3 个值,会让模型更好的提高准确度,也变得更加精简。它通过(经验?)发现这样的原则:
按照这个原则,Google 提出了 EfficientNet 系列,非常精简并且准确率高的模型。。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 from efficientnet_pytorch import EfficientNetfrom torch.optim import lr_schedulerfrom torchvision import transformsimport torchfrom torch import nndef conv3x3 (in_planes, out_planes, stride=1 ): return nn.Conv2d(in_planes, out_planes, kernel_size=3 , stride=stride, padding=1 , bias=False ) class ChannelAttention (nn.Module ): def __init__ (self, in_planes, ratio=16 ): super (ChannelAttention, self).__init__() self.avg_pool = nn.AdaptiveAvgPool2d(1 ) self.max_pool = nn.AdaptiveMaxPool2d(1 ) self.fc1 = nn.Conv2d(in_planes, in_planes // 16 , 1 , bias=False ) self.relu1 = nn.ReLU() self.fc2 = nn.Conv2d(in_planes // 16 , in_planes, 1 , bias=False ) self.sigmoid = nn.Sigmoid() def forward (self, x ): avg_out = self.fc2(self.relu1(self.fc1(self.avg_pool(x)))) max_out = self.fc2(self.relu1(self.fc1(self.max_pool(x)))) out = avg_out + max_out return self.sigmoid(out) class SpatialAttention (nn.Module ): def __init__ (self, kernel_size=7 ): super (SpatialAttention, self).__init__() assert kernel_size in (3 , 7 ), 'kernel size must be 3 or 7' padding = 3 if kernel_size == 7 else 1 self.conv1 = nn.Conv2d(2 , 1 , kernel_size, padding=padding, bias=False ) self.sigmoid = nn.Sigmoid() def forward (self, x ): avg_out = torch.mean(x, dim=1 , keepdim=True ) max_out, _ = torch.max (x, dim=1 , keepdim=True ) x = torch.cat([avg_out, max_out], dim=1 ) x = self.conv1(x) return self.sigmoid(x) class EfficientNetWithAttention (nn.Module ): def __init__ (self, num_classes: int = 200 ): super (EfficientNetWithAttention, self).__init__() self.eff_model = EfficientNet.from_pretrained("efficientnet-b7" ) self._avg_pooling = nn.AdaptiveAvgPool2d(output_size=1 ) self._dropout = nn.Dropout(p=0.5 , inplace=False ) self.fc = nn.Linear(in_features=2560 , out_features=num_classes, bias=True ) self.ca_head = ChannelAttention(64 ) self.sa = SpatialAttention() self.ca_tail = ChannelAttention(2560 ) def forward (self, x ): x = self.eff_model.extract_features(x) x = self.ca_tail(x) * x x = self.sa(x) * x x = self._avg_pooling(x) if self.eff_model._global_params.include_top: x = x.flatten(start_dim=1 ) x = self._dropout(x) x = self.fc(x) return x
最后准确率在 81% 左右,大小仅仅需要 200+MB,比前一个小多了!
学习率调整函数
一般来说,我们希望在训练初期学习率大一些,使得网络收敛迅速,在训练后期学习率小一些,使得网络更好的收敛到最优解。
固定步长衰减
使用 torch.optim.lr_scheduler.StepLR
1 2 optimizer_StepLR = torch.optim.SGD(net.parameters(), lr=0.1 ) StepLR = torch.optim.lr_scheduler.StepLR(optimizer_StepLR, step_size=step_size, gamma=0.65 )
其中gamma参数表示衰减的程度,step_size参数表示每隔多少个step进行一次学习率调整
ReduceLROnPlateau
使用 torch.optim.lr_scheduler.ReduceLROnPlateau
他可以基于训练中的某些测量值对学习率进行动态下降。
1 2 torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min' , factor=0.1 , patience=10 , verbose=False , threshold=0.0001 , threshold_mode='rel' , cooldown=0 , min_lr=0 , eps=1e-08 )
mode 可选择 min 或者 max ,min 表示当监控量停止下降的时候,学习率将减小,max 表示当监控量停止上升的时候,学习率将减小。
factor 学习率每次降低多少。new_lr = old_lr * factor
min_lr,学习率的下限
写在最后
感觉软工这个项目确实学到了点深度学习和人工智能的东西,但又说不上来(还是太菜了)。2020 年要结束了,今年的工作绝不拖到明年做!先这样子了,忙去复习期末了,等有空了还会捡起来接着做的!数学不好感觉学不明白…
下一步大概是尝试异元的 BCNN,一个用 EfficientNet 和另一个用 EfficientNet + Attention。还有就是提取特征后使用 SVM 或者一些拟合函数来训练,希望能突破85% 的准确率吧。
参考