deep-learning-intro
深度学习中的数学基础
软工作业 Week 2
- 概率是基础
- 支持向量机涉及很多数学基础
- 梯度下降是神经网络的共同基础
矩阵线性变换
对于给定的矩阵 A,假设其特征值为 ,特征向量为x,则他们之间的关系如下:
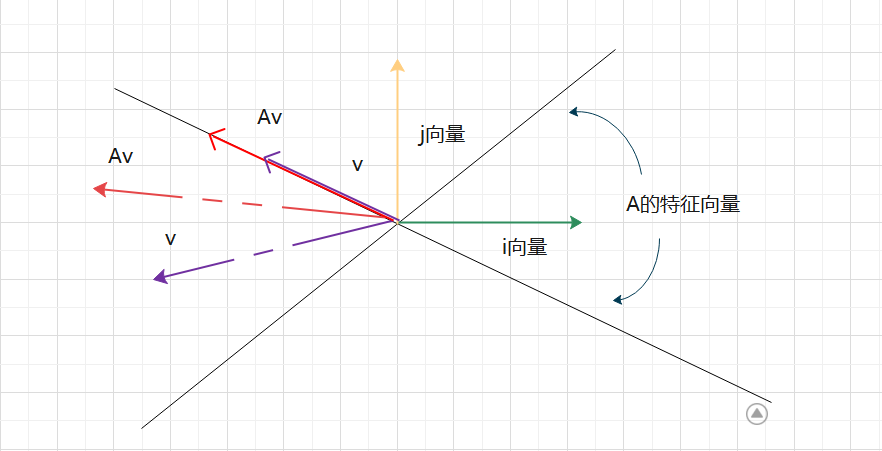
矩阵 A 对于 A 的特征向量做线性变换的时候,方向不再发生变化。
- 从线性变换的角度,矩阵相乘对原始向量同时施加方向变化和尺度变化。
- 对于有些特殊的向量,矩阵的作用只有尺度变化而没有方向变化,这类向量就是特征向量,变化系数就是特征值
矩阵的秩
-
线性方程组的角度:
- 度量矩阵行列之间的相关性
- 如果矩阵的各行或列是线性无关的,矩阵就是满秩的,也就是说秩等于行数
-
数据点分布的角度:
- 表示数据需要的最小的基数量
- 数据分布模式越容易被捕捉,即需要的基越少,秩就越小
- 数据冗余度越大,需要的基就越小,秩越小
- 若矩阵表达的是结构化信息,如图像,用户-物品表等,个行之间存在一定相关性,一般是低秩的
低秩近似
较大奇异值包含了矩阵的主要信息,只保留前r个较大奇异值及其对应的特征向量,一般 r 取 d 的十分之一就可以保留足够信息,可以实现数据从 n x d 维降维到 n x r + r x r + r x d
矩阵低秩近似:
图像去噪:数据矩阵X一般同事包含结构信息和噪声
矩阵分解为两个矩阵的相加,一个是低秩的(结构信息造成行或列间线性相关)另一个是稀疏的(噪声是稀疏的),很多问题中都会有这样类似的优化方法,写成函数如下:
概率函数形式统一
同一个模型可以用概率形式和函数形式来表示
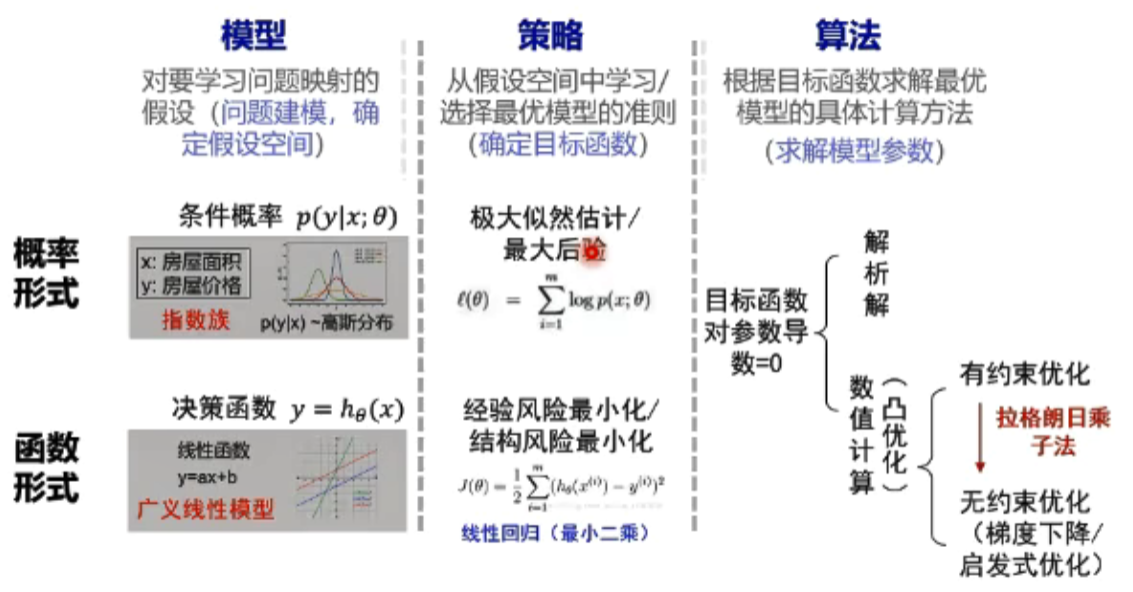
指数族:对常见分布标准化的形式;广义线性模型:线性回归,逻辑回归都是广义线性回归
指数族决定是高斯分布,那么广义线性模型就是线性回归模型。
例子:对于逻辑回归模型,假定的概率分布是伯努利分布,根据伯努利分布的定义,其概率质量函数 PMF 为:
似然函数可以写成:
常规操作——取对数,然后求最大化的对数似然
这个公式的每个加数子项表示单个样本的对数损失:若yi=1,P(y=1|x)越大损失越小;yi=0,P(y=1|x) 越小损失越小。
这些样本的损失,实际上和逻辑回归的经验风险损失很相近,逻辑回归也可以直接采用对数损失函数通过经验风险最小化求参,而经验风险最小化策略与极大似然策略优化得到的模型参数是一致的。
策略设计
衡量训练误差与泛化误差的差异:计算学习理论,它得出来一个结论——训练误差与泛化误差的差异和训练样本样本量与模型的复杂程度有关,样本量越大误差越小,模型越复杂差异越大
PAC 理论给出了实际训练学习器的目标
- 从合理数量的训练数据中通过合理计算量学习到可靠的知识(置信度高)
奥卡姆剃刀原理
如无必要,勿增实体:简单有效原理(说白了,如果你有两个方案,选择最简单的,多出来的东西并非有益,反而会带来麻烦)
如果多种模型能够同等程度地符合一个问题的观测结果,那么应该选择其中使用假设最少的最简单的模型
过拟合&欠拟合
欠拟合:训练集的一般性质没有被学习器学好(训练误差大)
- 提高模型复杂度
- 决策树:拓展分支
- 神经网络:增加训练轮数
过拟合:学习器把训练集特点当做样本一般的特点(训练误差小,测试误差大)
- 降低模型复杂度
- 优化目标加正则项
- 决策树:剪枝
- 神经网络:early stop, dropout
- 数据增广(扩大数据训练集):如计算机视觉可以将图像旋转,缩放,剪切;自然语言处理中可以将同义词替换;语音识别中可以加入随机噪声。
损失函数
BP 神经网络和损失函数:
如果设定,损失函数
令 为每个样本的平方损失代价
待优化参数:权重
待优化算法:梯度下降,需要计算代价函数L和梯度
更新公式:
平方损失
计算困难,采用交叉熵(对数损失函数)
巴拉巴拉…听不懂了这里,改天再改改
概率学派&贝叶斯学派
- 频率学派:关注可独立重复的随机试验中单个事件发生的频率,假设概率是客观存在的并且是固定的。这样得出的模型参数唯一,需要从有限的观测数据中估计参数值。
- 贝叶斯学派:关注随机事件的"可信程度",在数据之上加入假设,数据作用是对初始的假设做出修正,使观察者对概率的主观认识(先验)更接近客观实际(观测);模型参数本身是随机变量,需要顾及参数的整个概率分布。

深度学习概述
Yule-Simpson 悖论
相关性并不可靠,会因为一些混杂因素而改变。
因果性=相关性+忽略的因素
卷积神经网络(Convolutional Neural Network)
全连接网络处理图像的问题:
- 参数太多:权重矩阵的参数太多 -> 过拟合
卷积神经网络的解决方式:
- 局部关联,参数共享
卷积神经网络的应用
- 分类
- 检索
- 检测
- 分割
- 人脸识别,人脸验证
- 表情识别,图像生成,图像风格转化,自动驾驶
- …
卷积
一维卷积经常用在信号处理中,用于计算信号的延迟累积。假设一个信号发生器在时刻 t 发出一个信号xi,其信息衰减率为 fk,即在 k-1 个时间步长后,信息衰减为原来的 fk 倍。
我们设 f1=1,f2=0.5,f3=0.25,在 t 时刻收到的信号 yt 为当前时刻产生的信息和以前时刻延迟信息的叠加:
此处的 被称为滤波器(filter)或者叫卷积核(convolutional kernel),假设滤波器 f 的长度为 m,它和一个信号序列
的卷积记为
那么卷积是什么?
convolution is an operation on two functions of a real-valued argument.
卷积是对两个实变函数的一种数据操作
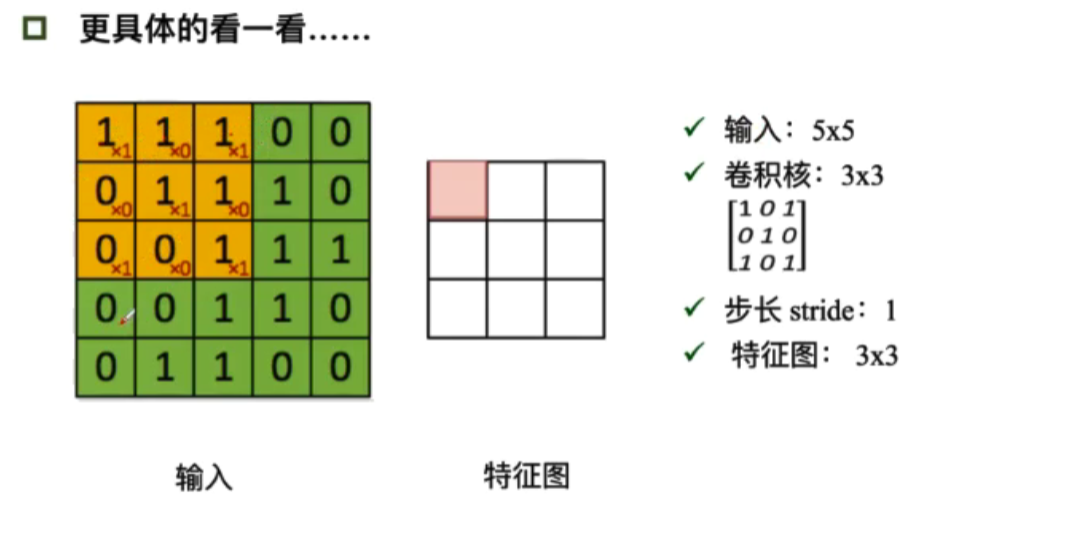
卷积核的输出等于卷积核的与输入对应位置的内积(逐个对应相乘再相加),粉色位置的值应为4(=1x1+1x0+1x1+0x0+1x1+1x0+0x1+0x0+1x1),步长为1,每次向右移动1格,这样特征图每一行就有3个数值了。
但有的时候,我们的输入无法被指定的步长分割好,这时候往往加入 padding,即在最外圈补一定数量的0
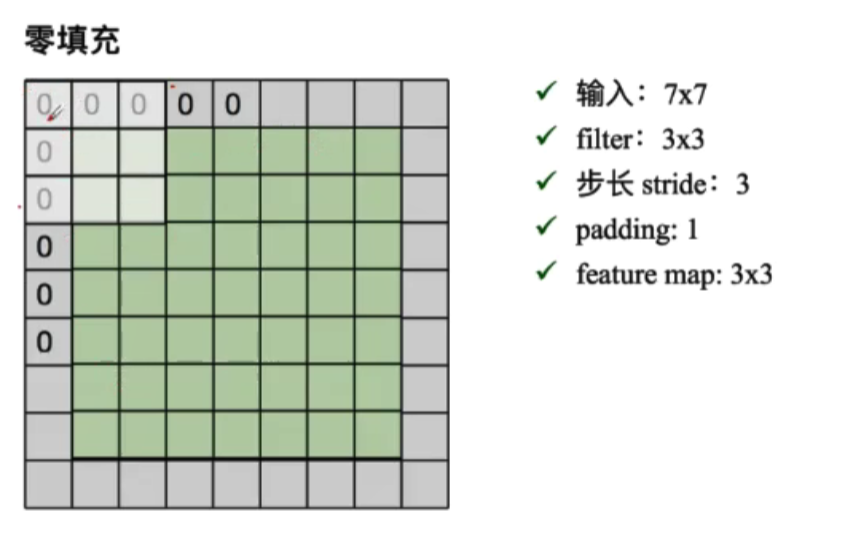
输出的特征图的大小:
- (N(input_scale)-F(filter_scale))/stride(step)+1
- (N+padding*2-F)/stride+1
加入深度:会直接影响输出的层数,有几层特征图的输出同样也有几层,(相当于使用不同的卷积核处理的次数?)。
池化(Pooling)
- 保留了主要特征的同时减少参数和计算量,防止过拟合来提高模型的泛化能力
- 一般处于卷积层和卷积层之间,全连接层与全连接层之间
常用的有最大值池化和平均值池化:
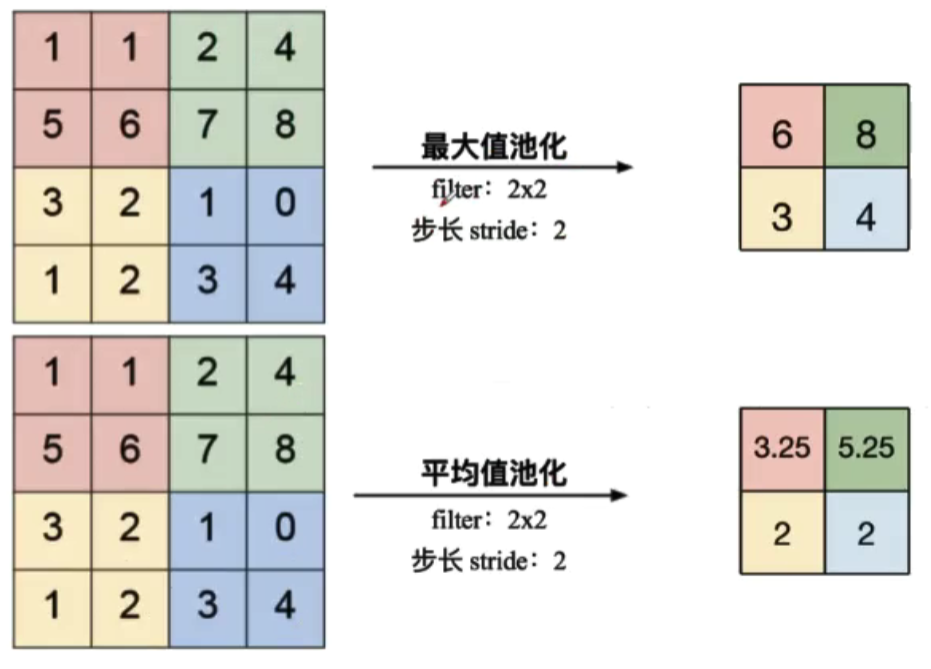
分类识别任务的时候,最大值池化比平均值池化效果更好。
全连接(Fully Connecting)
全连接层(FC layer)
- 两层之间的所有神经元都有权重链接
- 通常全连接层在卷积神经网络尾部
- 全连接层参数量通常很大
各种深度学习的模型概述
AlexNet
ReLU 激活函数的优点:
- 解决了梯度消失的问题
- 计算的速度很快,只需要判断输入是否大于0
- 收敛速度远快于 sigmod
使用 dropout 来防止过拟合: 训练的时候随机关闭一些神经元,测试时整合所有的神经元。
ZFNet
网络结构和 AlexNet 相同,将卷积层1中的感受野大小由11x11改为7x7,步长改为2,同时修改了3,4,5层滤波器的个数。
VGG
加深了 AlexNet 的层数,由8层变为了16,19层
GoogleNet
- 网络包含22个带参数的层,参数量大概是Alexnet的1/12。
- 使用不同的卷积核来增加特征的多样性
- 使用辅助分类器来解决模型深度过高导致过拟合
ResNet
残差学习网络(deep residual learning network)
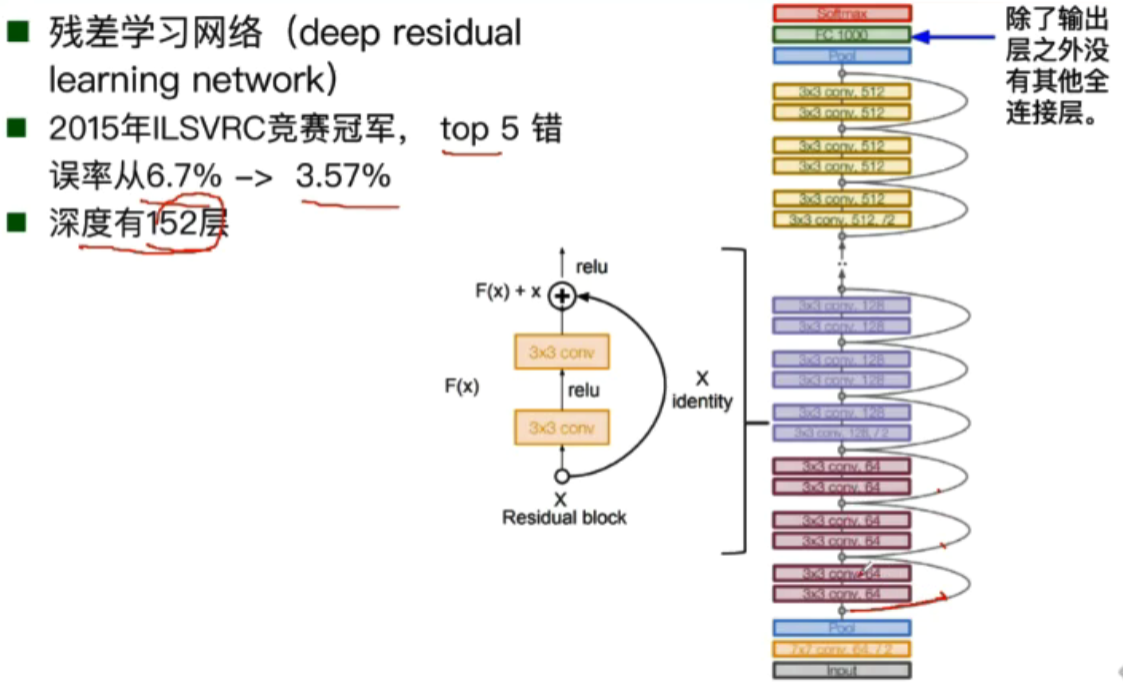
运用了残差的思想:去掉相同的主体部分,从而突出微小的变化,可以被用来训练非常深的网络。
deep-learning-intro