deffloyd(graph_matrix): n = len(graph_matrix) # 构造 path 数组 path = [] for i inrange(n): path.append([]) # 初始化 for i inrange(n): for j inrange(n): path[i].append(j)
for k inrange(n): for i inrange(n): for j inrange(n): if graph_matrix[i][k] == sys.maxsize or graph_matrix[k][j] == sys.maxsize: continue temp = graph_matrix[i][k] + graph_matrix[k][j] if temp < graph_matrix[i][j]: graph_matrix[i][j] = temp # 更新路径 path[i][j] = path[i][k] return graph_matrix, path
defshortest_path(graph_matrix, d): """ :param graph_matrix: 邻接矩阵 :param d: 度数组 :return: 最短路径 """ # 度为奇数的顶点 graph_matrix, _ = floyd(graph_matrix) odd_points = [0] # 初始化包含0便于后续dp数组dp[0]的计算 for i, di inenumerate(d): if di % 2 == 1: odd_points.append(i) # 奇度顶点的个数 odd_num = len(odd_points) - 1 dp = [0] # dp[0] 无一个点所以长度也为0 dp_length = 1 << odd_num # 初始化数组填入最大的数 for i inrange(dp_length): dp.append(sys.maxsize) for i inrange(dp_length): x = 1 while (1 << (x-1)) & i: # 选择不在当前集合的点x x += 1 for y inrange(x+1, odd_num+1): # x+1 <= y <= odd_num # 选择不在集合内的与x不同的y if (1 << (y-1)) & i: continue else: # 计算 binary_pt = i | (1 << (x-1)) | (1 << (y-1)) # 新形成的集合 if graph_matrix[odd_points[x]][odd_points[y]] == sys.maxsize: # x,y 不连通 pass elif dp[i] == sys.maxsize: # 对于这个组合无最短路径 pass else: trail = dp[i] + graph_matrix[odd_points[x]][odd_points[y]] # 更新最短路径 dp[binary_pt] = min(dp[binary_pt], trail) # print(dp[dp_length-1]) return dp[dp_length-1]
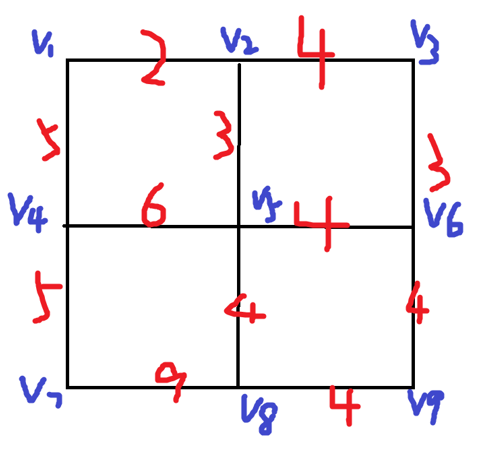
defmain(): # 记录的所有路求和 n = 0 d = [] min_length = 0 withopen("中国邮递员问题测试数据1.txt", 'r') as fp: scales = fp.readline() n, m = map(int, scales.split(' ')) # 初始化 for i inrange(n): d.append(0) graph = [[sys.maxsize]*n for _ inrange(n)] # 读入数据 for line in fp.readlines(): start_point, end_point, weight = map(int, line.split(' ')) # 点标号从 1 开始 start_point -= 1 end_point -= 1 d[start_point] += 1 d[end_point] += 1 # 无向图 graph[start_point][end_point] = weight graph[end_point][start_point] = weight min_length += weight print(graph) print("最小路径长度为:", end='') t = 0 for di in d: if di % 2 == 0: t += 1 if t == n: # 所有点读数都是偶数度,为欧拉图 pass else: min_length += shortest_path(graph, d) print(min_length)
需要找O(n)次增广路,每次增广最多需要修改O(n)次顶标,每次修改顶标时由于要枚举边来求 d 值,复杂度为O(n^2)
实际上 KM 算法的复杂度是可以做到O(n^3)的。我们给每个 Y 顶点一个"松弛量" slack,每次开始找增广路时初始化为无穷大。在寻找增广路的过程中,检查边(i,j)时,如果它不在相等子图中,则让slack[j]变成原值与 x[i]+y[j]-w[i][j] 的较小值。这样在修改顶标时,取所有不在交错树中的 Y 顶点的 slack 值中的最小值作为 d 值即可。但还要注意一点:修改顶标后要把所有不在交错树中的 Y 顶点的 slack 值都减去d
def__init__(self, graph: dict): self.graph = graph # 初始化均未被访问 for p in graph.keys(): self.visit_x[p] = False self.lx[p] = -1 self.visit_y[p] = False self.ly[p] = -1 self.match[p] = -1
def_extended_path(self, x): # 寻找增广路径 # x 点被选择 self.visit_x[x] = True for y in self.visit_y.keys(): if self.visit_y[y]: # 结点被访问过了 continue if self.graph[x][y] == sys.maxsize: # 不连通 continue temp = self.lx[x] + self.ly[y] - self.graph[x][y] if temp == 0: # x, y 在相等子图中 self.visit_y[y] = True if self.match[y] == -1or self._extended_path(self.match[y]): # 如果 y 元素没有对应的匹配或者 y 有新的匹配点 self.match[y] = x returnTrue elif self.slack[y] > temp: # slack 优化 self.slack[y] = temp else: pass # 无增广路径 returnFalse
def_solve(self): for x in self.visit_x: # 对所有的 x 寻找增广回路 # 重新初始化 slack 中的数值 for y in self.visit_y: self.slack[y] = sys.maxsize whileTrue: # 求新的增广回路,重新初始化访问数组 for y in self.visit_y: self.visit_y[y] = False for xt in self.visit_x: self.visit_x[xt] = False if self._extended_path(x): # 有增广回路 break# 跳出循环,判断下一个点 else: delta = sys.maxsize # 求得需要对定标进行运算的 d for y in self.visit_y: # y 在交错树外,x 在交错树中(dfs失败x一定在交错树中) if (not self.visit_y[y]) and delta > self.slack[y]: delta = self.slack[y] # 对定标的值修正,下一步一定可以再加入一个点 for xt in self.visit_x: if self.visit_x[xt]: self.lx[xt] -= delta for yt in self.visit_y: if self.visit_y[yt]: self.ly[yt] += delta else: # 修改顶标后,要把所有的slack值都减去delta # 这是因为x点的标定值减小了delta # 根据slack的计算也需要变换和x点相关的点的slack值 self.slack[yt] -= delta
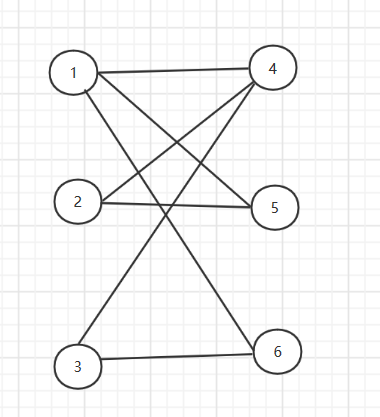
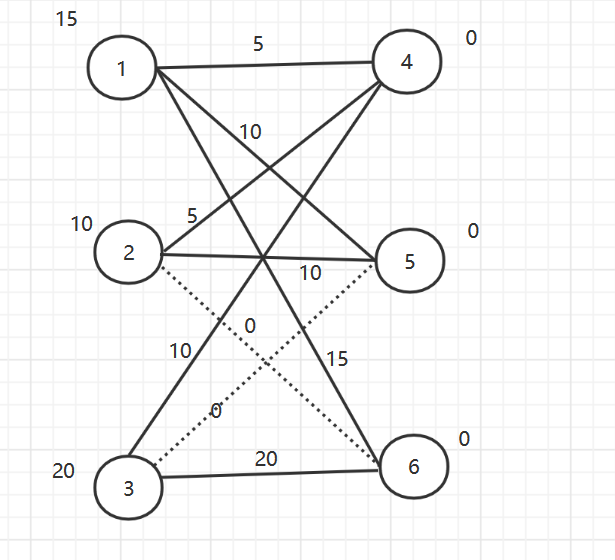
defkm_solve(self, is_max=True): # 初始化 ifnot is_max: for v_dict in self.graph.values(): for pv in v_dict: v_dict[pv] = -v_dict[pv] for x in self.lx: # 贪心算法, 初始化为点最大的权的边 self.lx[x] = max(list(self.graph[x].values())) for y in self.ly: self.ly[y] = 0 self._solve() part_match = {} temp_s = 0 for k, v in self.match.items(): temp_s += self.graph[k][v] if k in part_match.keys() or k in part_match.values(): pass else: part_match[k] = v self.match = part_match print(part_match) print(temp_s) # 匹配整体计算了2次 if is_max: return temp_s / 2 else: return -temp_s / 2
一点点细节
到此我们已经可以解决这个问题了,但好像只剩完成了求解长度的部分,那路径呢???
其实这个题目最难的是求回路路径
对于 Floyd 算法,我们求最短的路径时同时要记录节点
适当调整 Fleury 算法的实现:对于带平行边的图的存储,使用邻接矩阵时用a[i][j] = k表示 ij 直接有 k 条平行边,当要删除边时a[i][j]-=1,恢复边的时候a[i][j]+=1
defsolve(self, current, start): flag = False# 是否还有与x关联的边 # 倒回会导致上一个点被多记录一次 if self.route and self.route[-1] == current: pass else: self.route.append(current) for i inrange(start, self.num): # 从 start 开始搜索是否有边 if self.graph[i][current] > 0: # i 与 current 有边 flag = True # 删除边 self.graph[i][current] -= 1 self.graph[current][i] -= 1 self.solve(i, 0) # 从 i 开始搜索 break ifnot flag: # 如果没有边与当前节点 current 相连 print(self.route) self.route.pop() # if len(self.route) == self.num: # return self.route if self.all_zeros(): self.route.append(start) return self.route else: # 回溯 temp = self.route[-1] # 恢复上一次的 2 条边 self.graph[temp][current] += 1 self.graph[current][temp] += 1 new_start = current + 1 # 路径包含所有的点 self.solve(temp, new_start)
defall_zeros(self): for i inrange(0, self.num): for j inrange(0, self.num): if self.graph[i][j] != 0: returnFalse returnTrue
# km求解中国邮递员.py import sys from fleury import Fleury from km import KM
defeuler(index, edge): f = Fleury(edge) f.solve(index, index) return f.route
deffloyd(graph_matrix): n = len(graph_matrix) # 构造 path 数组 # 如果没有清 0 我们需要手动清0 for i inrange(n): graph_matrix[i][i] = 0 path = [] for i inrange(n): path.append([]) # 初始化 for i inrange(n): for j inrange(n): path[i].append(j)
for k inrange(n): for i inrange(n): for j inrange(n): if graph_matrix[i][k] == sys.maxsize or graph_matrix[k][j] == sys.maxsize: continue temp = graph_matrix[i][k] + graph_matrix[k][j] if temp < graph_matrix[i][j]: graph_matrix[i][j] = temp # 更新路径 path[i][j] = path[i][k]
for i inrange(n): graph_matrix[i][i] = sys.maxsize
return graph_matrix, path
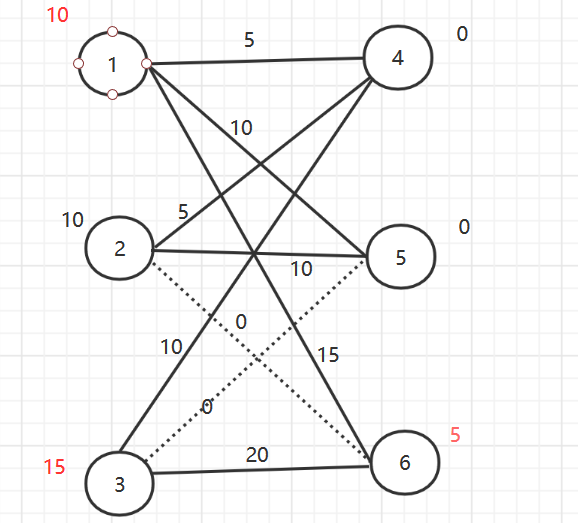
d = [] min_length = 0 adjacency_array = [] # 邻接矩阵,用起来完全不是邻接矩阵......不想改了 withopen("中国邮递员问题测试数据2.txt", 'r') as fp: scales = fp.readline() n, m = map(int, scales.split(' ')) # 初始化 for i inrange(n): d.append(0) graph = [[sys.maxsize]*n for _ inrange(n)] adjacency_array = [[0]*n for _ inrange(n)] # 读入数据 # 要求读入的数据要满足邻接表的排布 for line in fp.readlines(): start_point, end_point, weight = map(int, line.split(' ')) # 输入的点标号从 1 开始 start_point -= 1 end_point -= 1 # 构造邻接矩阵 adjacency_array[start_point][end_point] += 1 adjacency_array[end_point][start_point] += 1 d[start_point] += 1 d[end_point] += 1 # 无向图 graph[start_point][end_point] = weight graph[end_point][start_point] = weight min_length += weight t = 0 for di in d: if di % 2 == 0: t += 1 if t == n: # 所有点读数都是偶数度,为欧拉图 route = euler(0, adjacency_array) else: odd_points = [] # 记录奇数度顶点的数组 for i, di inenumerate(d): if di % 2 == 1: odd_points.append(i) # 奇度顶点的个数 graph_matrix, path = floyd(graph) # 奇度顶点组成子图 sub_graph = {} for odd_p in odd_points: sub_graph[odd_p] = {} for end_p in odd_points: sub_graph[odd_p][end_p] = graph_matrix[odd_p][end_p] km_solution = KM(sub_graph) # 求最小解 min_length += km_solution.km_solve(False) # 删去匹配的边 for k, v in km_solution.match.items(): start = k temp = path[k][v] whileTrue: # 存在中转的情况, 以中转为起点 adjacency_array[start][temp] += 1 adjacency_array[temp][start] += 1 if temp == v: break else: pass start = temp temp = path[temp][v]
route = euler(0, adjacency_array) for p in route: print("({})".format(p+1), end='') print("最小路径长度为:", end='') print(min_length)