
程序员的自我修养-可执行文件的装载
可执行文件的装载与进程
可执行文件只有装载到内存以后才能被 CPU 执行。早期的程序装载十分简陋,装载的基本过程就是把程序从外部存储器中读取到内存中的某个位置。随着硬件 MMU 的诞生,多进程,多用户,虚拟存储的操作系统出现,可执行文件的装载过程变得非常复杂。
进程虚拟地址空间
我们知道每个程序被运行起来以后,它将拥有自己独立的虚拟地址空间(Virtual Address Space),这个虚拟地址空间的大小将由计算机的硬件平台决定,具体地说是由 CPU 的位数决定。硬件决定了地址空间的最大理论上限。如32位 CPU 具有32位寻址能力,4GB 的虚拟空间大小。
进程只能使用那些操作系统分配给进程的地址,如果访问未经允许的空间,那么操作系统就会捕获这些访问,将进程的这种访问当做非法操作,强制结束进程。
对于 Linux 系统来说,默认情况下 Linux 操作系统将进程的虚拟空间分为2部分,操作系统使用从 0xC0000000 到 0xFFFFFFFF 的空间,而剩下的空间应用程序使用。但是对于某些程序,这样的内存大小太小了,怎么办?
PAE
从硬件层面讲,原先的32位地址线只能访问最多4GB的物理内存。但自从扩展至36位地址线之后,Intel 修改了页映射的方式,使得新的映射方式可以访问到更多的物理内存。 Intel 把这个地址扩展方式叫做 PAE(Physical Address Extension)
当然扩展的物理地址空间,对于普通应用程序来说正常情况下感觉不到它的存在,因为这主要是操作系统的事,在应用程序中,只有32位的虚拟地址空间,那么应用程序该如何使用这些大于常规的内存空间?一个很常见的方法就是操作系统提供一个窗口映射的方式把这些额外的内存映射到进程地址空间来。应用程序可以根据自己的需要来选择申请和映射,比如一个应用程序中 0x10000000~0x20000000 这一段256MB的空间用来做窗口,程序可以从高于4GB的物理空间中申请多个大小为256MB的物理空间,编号为A,B,C等,然后根据需要将这个窗口映射到不同的物理空间块,用到 A 时将 0x10000000~0x20000000 映射到 A,用到 B 时就映射到 B。在 Windows 下,这种内存的操作方式叫做 AWE(Address Windowing Extensions),而像 UNIX 类操作系统则采用 mmap() 系统调用来实现。
装载的方式
程序执行时所需要的指令和数据必须在内存中才能正常运行,最简单的方法就是将程序运行需要的指令和数据全部装入内存中,虽然这样程序就可以顺利运行,但是实际情况很多时候是内存不够。为了尽可能高效利用内存,我们可以将程序的最常用的部分驻留在内存,而将一些不常用的数据存放到磁盘里,这就是动态装入的基本原理。动态装入的方式有覆盖装入(Overlay),页映射(Paging)
覆盖装入
比较老的方法,这个方法需要人工的将程序分割为若干块,然后编写一个小的辅助代码来管理这些模块该何时驻留内存而该何时被替换掉。这个小的辅助代码就是所谓的覆盖管理器(Overlay Manager)。太老了不多介绍,我们把精力放在页映射中。
页映射
页映射是虚拟存储机制的一部分,它随着虚拟内存的发明而诞生。前面我们已经介绍了页映射的基本原理,这里我们再结合可执行文件的装载来阐述一下页映射是如何被应用的。与覆盖装入的原理相似,页映射也不是一下子就把程序的所有的数据和指令都装入内存,而是将内存和所有磁盘中的数据和指令按照 “页” 为单位划分为若干个页,以后所有的装载和操作的单位就是页。
现在我们假设我们的32位机器有16KB的内存,每个页的大小为4096字节,则共有4个页。
| 页编号 | 地址 |
|---|---|
| F0 | 0x00000000~0x00000FFF |
| F1 | 0x00001000~0x00001FFF |
| F2 | 0x00002000~0x00002FFF |
| F3 | 0x00003000~0x00003FFF |
假设程序所有的指令和数据总和为32KB,那么程序总共被分为8个页。我们将它们编号为 P0~P7。明显,16KB的内存无法同时将32KB的程序装入,那么我们将按照动态装入的原理来进行整改装入过程,如果程序刚开始执行时的入口地址为 P0,这时装载管理器(我们假设装载过程由一个叫装载管理器的控制程序),发现 P0 不在内存中,就将内存 F0 分配给 P0,并将 P0 的内容装入 F0 。一段时间后,又用到了 P5,于是装载管理器将 P5 装入 F1,就这样,当需要的时候装入。如果满了,就需要放弃正在使用的一个内存页来装入新的内存页,这时有多种算法来决定选择舍弃哪个。(舍弃先装入的,舍弃不常用的)。
这个所谓的装载管理器就是现代的操作系统,更具体的说,就是操作系统的存储管理器。目前几乎所有的主流操作系统都是按照这种方式装载可执行文件的。
从操作系统的角度看可执行文件的装载
进程的建立
很多时候,一个程序的执行同时都伴随着一个新的进程的创建,那么我们就来看看这种最通常的情形:创建一个进程,然后装载相应的可执行文件并且执行。在有虚拟内存的情况下,上述过程最开始只需要做这三件事:
- 创建一个独立的虚拟地址空间
- 读取可执行文件头,并且建立虚拟空间与可执行文件的映射关系
- 将 CPU 的指令寄存器设置成可执行文件的入口地址,启动运行
首先是创建虚拟地址空间。一个虚拟空间由一组页映射函数将虚拟空间的各个页映射至相应的物理空间,那么创建一个虚拟空间实际上并不是创建空间而是创建映射函数所需要的相应的数据结构。在 i386 的 Linux 下,创建虚拟地址空间实际上只是分配了一个页目录(Page Directory)就可以了,甚至不需要设置页映射关系,这些映射关系等到程序发生页错误的时候再去设置。
读取可执行文件头,并且建立虚拟空间与可执行文件的映射关系。上面那一步的页映射关系函数是虚拟空间到物理内存的映射关系,这一步所做的是虚拟空间与可执行文件的映射关系。我们知道,当程序执行发生页错误时,操作系统将从物理内存中分配一个物理页,然后将缺页的部分读取入内存,再设置映射关系,这样程序就可以正常运行。但是它如何知道程序当前所需要的页在可执行文件中的哪个位置?
由于可执行文件在装载时实际是被映射的虚拟空间,所以可执行文件很多时候也被称为映像文件(Image)
让我们考虑一个最简单的情况,假设我们的 ELF 可执行文件只有一个代码段,它的虚拟地址为0x08048000,它在文件中的大小为0x000e1,对齐为0x1000。由于虚拟存储的页映射都是以页为单位的,在32位的 Intel IA32 下一般为4096字节,所以32位 ELF 的对齐粒度为 0x1000。由于该代码段大小不到一个页,考虑到对齐该段占用一个段。所以一旦该文件被装载,可执行文件与执行该文件进程的虚拟空间的映射关系如图
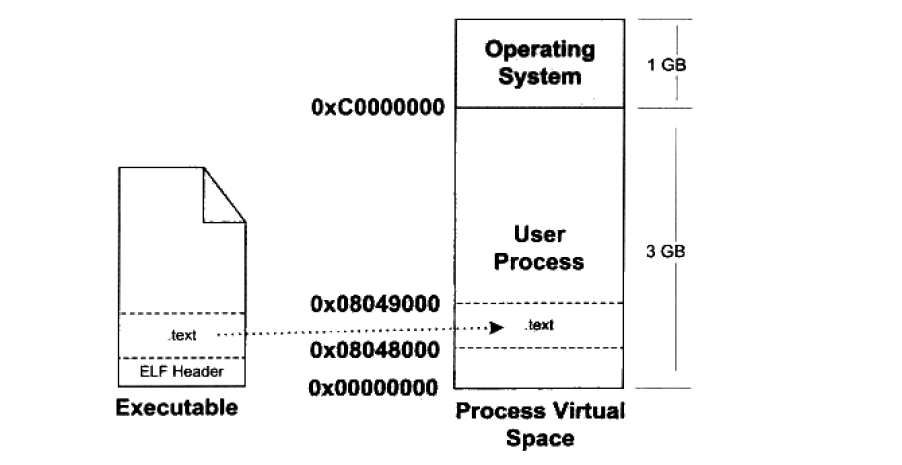
这种数据关系只是保存在操作系统内部的一个数据结构。 Linux 中将进程虚拟空间中的一个段叫做虚拟内存区域(Virtual Memory Area),操作系统创建进程后,会在进程相应的数据结构中设置一个有 .text 段的 VMA,它对于 ELF 文件中的 .text。
将 CPU 指令寄存器设置为可执行文件入口,启动运行。这一步看似简单:设置 CPU 指令寄出器的值为 ELF 文件头中的入口地址。实际在操作系统层面比较复杂,它涉及内核堆栈和用户堆栈的切换, CPU 运行权限的切换。
页错误(Page Fault)
上面的步骤执行完后,可执行文件真正的指令和数据还保留在硬盘里。操作系统知识通过可执行文件头部的信息建立起可执行文件和进程虚存之间的映射关系。假设在上面的例子中,程序的入口地址为 0x08048000,即刚好是 .text 段的起始地址。当 CPU 开始打算执行这个地址指令时,发现页 0x08048000~0x08049000 是个空页面,于是它认为这是一个页错误, CPU 将控制权交给操作系统,操作系统有专门的页错误处理例程来处理这种情况。这时操作系统将查询装载过程建立的数据结构,找到空页面所在的 VMA,计算出响应页面在可执行文件中的偏移,然后在物理内存中分配一个物理页面,将进程中该虚拟页与分配的物理页之间建立映射关系,然后把控制权再还给进程,进程从刚才页错误的位置重新开始执行。
进程虚拟空间分布
前面的例子中,可执行文件中只有一个代码段,当其被装载时对应的只有一个 VMA,实际情况会复杂的多,在一个正常的进程中,可执行文件中往往不止包含了代码段,还有数据段,BSS 等。所以映射到进程虚拟空间的往往不止一个段。当段的数量增多时。一个段的多余部分往往也会占一个页,一个文件中往往有十几个段,浪费了大量的空间。
为了节约空间,一个很简单的方法是:对于相同的权限的段,把他们合并到一起当做一个段来映射。因为操作系统只关心一些和装载有关的问题,最主要的是段的权限(可读,可写,可执行)
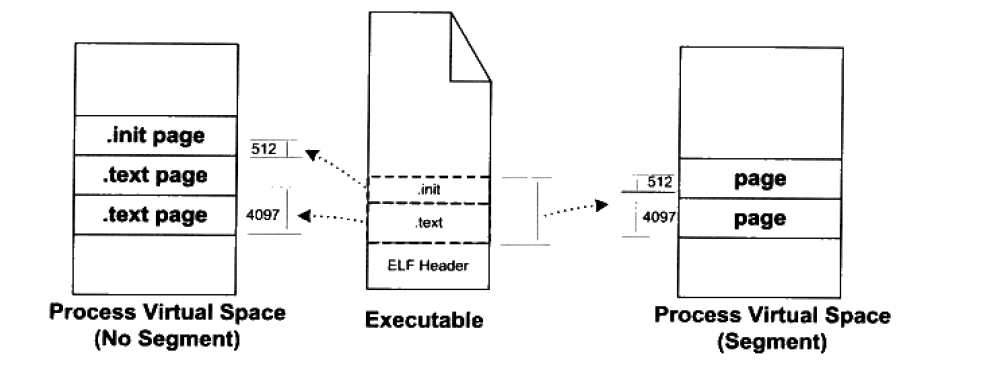
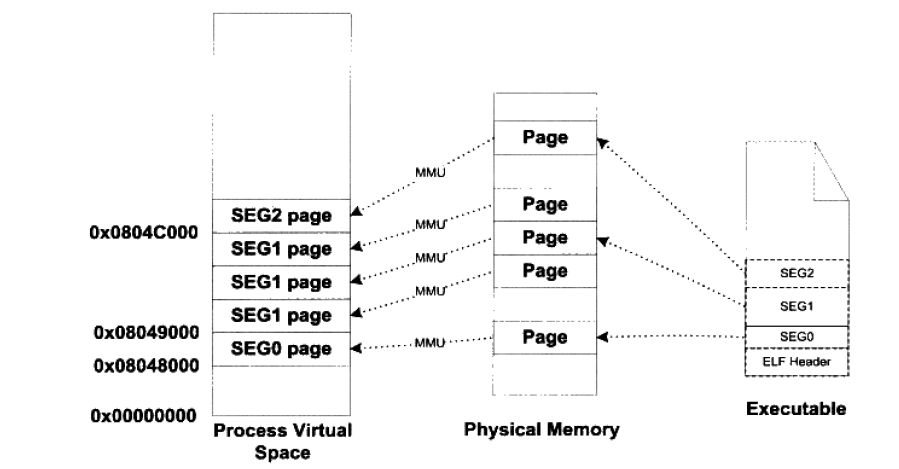
在将目标文件链接成可执行文件的时候,链接器会尽量把相同权限属性的段分配在同一空间。比如可读可执行的段都放在一起,这种段的典型是代码段,可读可写的段放在一起,这种段的典型就是数据段。在 ELF 文件中把这些属性相似的,又连在一起的段叫做 “Segment”, 而系统正是按照它来映射可执行文件的。
可以使用 readelf -l 来查看 ELF 如何被操作系统映射到进程的虚拟空间
1 | ...... |
在 ELF 可执行文件中有一个数据结构叫做程序头表(Program Header Table)
1 | /* Program segment header. */ |

- 对于 LOAD 类型的 Segment 来说,p_memsz 的值不可以小于 p_filesz,否则就装不下。当大于时,就表示在内存中分配的大小超过文件中的实际大小,多余的部分往往会被赋值为0,这样做的好处是,我们在构造 ELF 可执行文件时不需要额外设立 BSS 段,那些0的内存就是(多出来的内存) BSS。
堆和栈
在操作系统里面,VMA 除了被用来映射可执行文件中的各个 Segment 外,它还有其他的作用,操作系统通过使用 VMA 来对进程的地址空间进行管理。我们知道进程在执行时还需要**栈(Stack)和堆(Heap)**等空间。一个进程中的栈和堆都有相应的 VMA。
$ ./section_mapping.elf &
[1] 98
$ cat /proc/98/maps
00400000-004b5000 r-xp 00000000 00:00 23549 ./section_mapping.elf
004b5000-004b6000 r-xp 000b5000 00:00 23549 ./section_mapping.elf
006b6000-006bc000 rw-p 000b6000 00:00 23549 ./section_mapping.elf
006bc000-006bd000 rw-p 00000000 00:00 0
014e1000-01504000 rw-p 00000000 00:00 0 [heap]
7fffe5590000-7fffe5d90000 rw-p 00000000 00:00 0 [stack]
7fffe5f2b000-7fffe5f2c000 r-xp 00000000 00:00 0 [vdso]
- 第一列是 VMA 的地址范围,第二列是 VMA 的权限(p 表示私有),第三列是偏移,表示 VMA 对应的 Segment 在映像文件中的偏移。第四列表示映像文件所在的主设备和次设备号,第五列表示映像文件的节点号。最后一列是路径。
- 我们用 malloc 函数分配的空间就是从堆里分配的,堆由系统库管理。每个线程都有自己的堆栈,对于单线程的程序来说,这个 VMA 堆栈全部由它使用。另外地比较特殊的 VMA 叫做 “vdso”,它是一个内核的模块,进程可以通过访问这个 VMA 来跟内核进行一些通信。
- 由于是子系统,看起来栈和 vdso 都位于内核空间,不知道现在的 Linux 系统是不是也是这样。猜测也是子系统的缘故,堆对于当前 Linux 用户都无法执行(毕竟内核是 Windows 的)
- Linux 允许一个 VMA 没有映射到任何文件,所以会有上面的一个 VMA 没有映射到任何地方,有什么用呢?
//TODO 查明没有映射的 VMA 的作用
小结
小结一下关于进程虚拟空间的概念:操作系统通过给进程空间划分出一个个 VMA 来管理进程的虚拟空间,基本原则是将相同权限属性的,有相同映像文件的映射成一个 VMA,一个进程基本上可以分为如下几种 VMA 区域:
- 代码 VMA,只读可执行,有映像文件
- 数据 VMA,可读可写,有映像文件
- 堆 VMA,可读可写可执行,无映像文件,匿名,可向上(高地址)扩展
- 栈 VMA,可读可写,不可执行,无映像文件,匿名,可向下(低地址)扩展
段地址对齐
可执行文件最终是要被操作系统装载运行的,这个装载的过程一般是通过虚拟内存的页映射机制完成。在映射过程中,页是映射的最小单位。对于 Intel 80x86 系列处理器来说,默认的页大小为 4096 字节,也就是说,我们在一段物理内存和进程虚拟地址空间之间建立映射关系,这段空间必须是 4096 的整数倍。如果有大量的不满 4096 的内存空间需要映射,传统的方法就会带来大量的碎片。
为了解决这个问题,有些 UNIX 系统采取了一个方法:让接壤部分共享一个物理页面,然后再将该页面映射两次。
举个例子:假设一个 ELF 文件由3个 Segment(段)需要装载,分别为 SEG0(127字节),SEG1(9899字节),SEG2(1988字节)
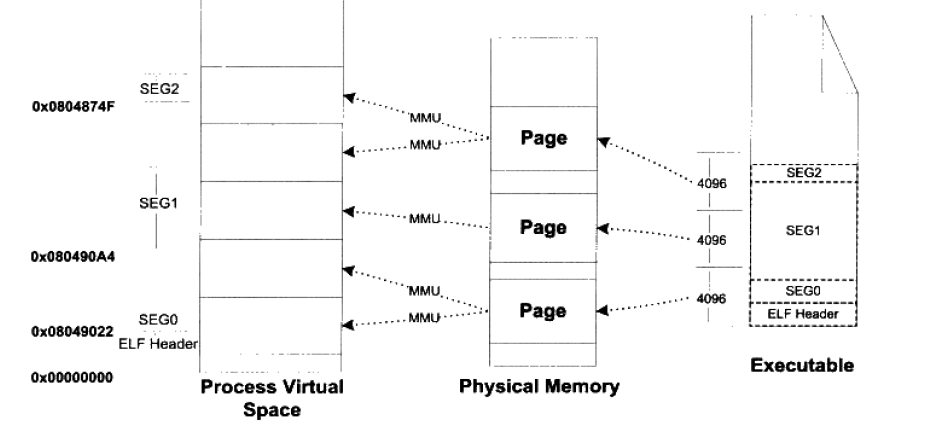
这种映射下,一个物理的页面里往往可能包含多个段,在 ELF 文件中,对于任何一个可装载的段,它的 p_vaddr 除以对齐属性的余数等于 p_offset 除以对齐属性的余数。
进程栈初始化
进程刚开始启动的时候,须知到一些进程运行的环境,最基本的就是系统环境变量和进程的运行参数,很常见的一种做法是操作系统在进程启动前将这些信息提前保存到进程虚拟空间的栈中(Stack VMA)
假设我们的系统变量为:
HOME=/home/user
PATH=/usr/bin
我们运行程序的命令为 prog 123
假设堆栈段底部的地址为 0xBF802000,那么进程初始化后的堆栈就如图:
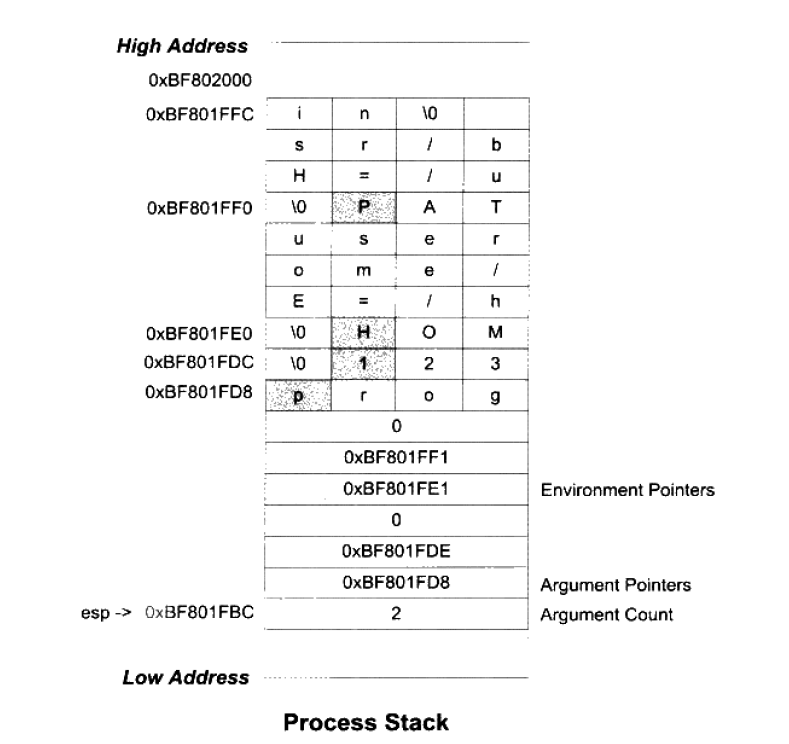
进程在启动以后,程序的库部分会把堆栈里的初始化信息中的参数信息传递给 main 函数,也就是我们熟知的 argc, argv 参数,分别对应命令行参数数量和命令行参数字符串指针数组。
Linux 内核装载 ELF 过程简介
当我们在 Linux 系统的 bash 下输入一个命令来执行某个 ELF 程序时,在用户层面, bash 进程会调用 fork() 系统调用创建一个新的进程,然后新的进程调用 execve() 系统调用执行 elf 文件。原先的 bash 进程继续返回等待刚才启动的新进程的结束。
1 |
在进入 execve() 系统调用之后,Linux 内核就开始进行真正的装载工作。在内核中,execve() 系统调用相应的入口是 sys_execve(),它被定义在 Process.c 文件中,sys_execve() 进行一些参数的检查复制后,调用 do_execve(),它会先查找文件,然后读取文件的前128个字节,判断文件格式,特别是开头的4个字节(魔数),通过它就能知道文件的格式和类型。比如 ELF 的可执行我呢间格式头4个字节为0x7F(“elf”),java 的为 “cafe”。对于 Shell 脚本或者 Python,它的第一行往往是 “#!/bin/sh” 或 “#!/usr/bin/python”,这时前两个字节 ‘#’ 和 ‘!’ 就构成了魔数。
之后就去搜索和匹配合适的可执行文件装载处理函数。我们这里只关心 ELF 可执行文件的装载,它的主要步骤是:
- 检查 ELF 可执行文件格式的有效性,比如魔数,程序头表中 Segment 的数量
- 寻找动态链接的 .interp 段,设置动态链接器路径
- 根据 ELF 可执行文件的程序头表的描述,对 ELF 文件进行映射,比如代码,数据,只读数据
- 初始化 ELF 进程环境
- 将系统调用的返回地址修改为 ELF 可执行文件的入口点,这个入口点取决于程序的链接方式,对于静态链接的 ELF 可执行文件,这个程序入口就是 ELF 文件的文件头中 e_entry 所指的地址,对于动态链接的 ELF 可执行文件,程序入口是动态链接器
这样 EIP 寄存器就会跳到合理的入口,当上述内核程序执行完后,ELF 文件开始执行。
程序员的自我修养-可执行文件的装载