
程序员的自我修养-静态链接
当我们有两个目标文件时,如何将它们链接起来形成一个可执行文件?这个过程中发生了什么?
静态链接
使用下面两个源码文件 a.c, b.c 来展开我们关于静态链接的学习
1 | /* a.c */ |
空间与地址分配
可执行文件中的代码段和数据段都是由输入的目标文件中合并而来的。那么链接器如何将多个段和并起来的?
按序叠加
最简单的方式就是将输入的目标文件按照次序叠加起来,但这样很明显对空间的浪费太严重,因为每个段都有一定的地址和空间对齐要求,这样造成了大量的空间浪费。
相似段合并
一个更实际的方法是将相同性质的段合并在一起。如把所有目标文件的 .data 合并到输出文件的 .data 段里。
关于 .bss 段,它在目标文件和可执行文件中并不占用文件的空间,但是它在装载时占用地址空间,所以链接器在合并各个段的同时也将 .bss 段合并,并且分配虚拟空间。
现在的链接器空间分配一般都采取相似段的合并的方法,使用这种方法的链接器一般都采用一种叫做**两步链接(Two-pass Linking)**的方法,也就是说整个链接过程分为两步:
两步链接法
-
- 空间与地址分配
- 扫描所有的输入目标文件,获取它们各个段的长度,属性和位置,并且将输入目标文件中的符号表中的所有的符号定义和引用收集起来,统一放到一个全局的符号表中。这一步中,链接器将能够获取所有输出目标文件的段长度,并且将它们合并,计算出输出目标文件中各个段合并后的长度和位置并且建立映射关系。
-
- 符号解析与重定位
- 使用上面一步收集到的所有信息,读取输入文件中段的数据,重定位信息,并且进行符号解析与重定位,调整代码中的地址。最重要的是重定位的过程。

- 自己尝试时无法用 ld 链接,使用 gcc 链接发现 gcc 加了很多的东西(动态链接),只好放截图
- VMA(Virtual Memory Address) 即虚拟地址, LMA(Load Memory Address) 即加载地址,正常情况下两个的值应该一样,但有些嵌入式系统中,特别是在那些程序放在 ROM 的系统中时,LMA 和 VMA 是不相同的。
- 在链接之前目标文件中的 VMA 都是0,因为虚拟空间还没有被分配。等到链接后,可执行文件 ab 的各个段都被分配到了相应的虚拟地址。
- 链接器将可执行文件 “ab” 的 .text 段分配到 0x08048094,.data 分配到 0x08049108,因为在 Linux 下 ELF 可执行文件默认从地址 0x08048000 开始分配。
符号地址的确定
当段的虚拟地址确定后,链接器需要计算各个符号的地址,由于在段内的相对位置固定,所以只需要给每个符号加一段偏移量就可以调整到正确的虚拟地址。
符号解析与重定位
重定位
在完成空间和地址的分配步骤后,链接器就进入了符号解析与重定位的步骤,这是静态链接的核心内容。
使用 objdump -d a.o 来查看代码反汇编的结果,我们把注意力放在这几条命令中:
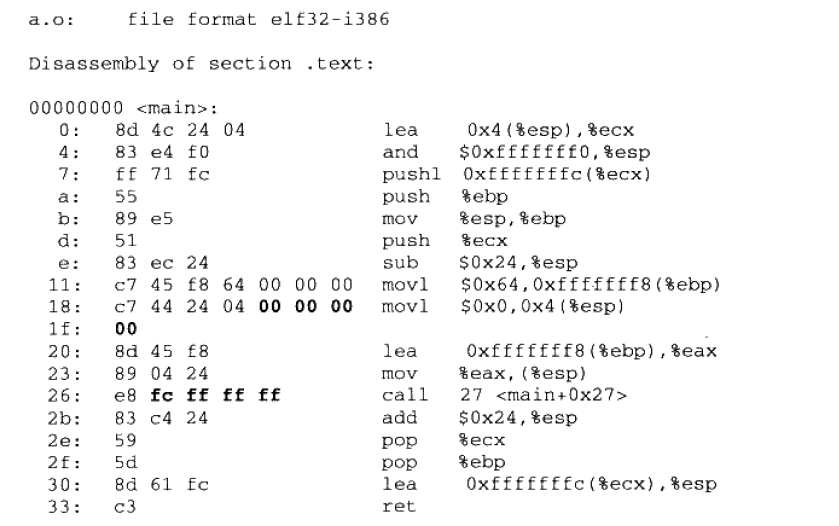
e8 fc ff ff ff call 27 <main+0x27> 以及 c7 44 24 04 00 00 00 movl $0x0, 0x4(%esp)
- main 的起始代码为0,这是因为并没有分配空间。
- 在编译阶段,编译器并不知道 shared 和 swap 的地址,因此编译器暂时把0看做 shared 的地址,所有和 shared 相关的地址全部为0x0
- 而 swap, E6 是 call 的机器码,而后面的数
FC FF FF FF是小端存储的数字, 为-4。 call 是一条近地址相对位移调用指令(Call near, relative, displacement relative to next instruction),即相对于调用指令的下一条指令的偏移量,这里我们的地址是一个临时的假地址。

- 这时我们再重新计算 call 的目标地址,发现是正确的,因为链接器以及重新计算好了符号的地址。
重定位表
链接器如何知道哪些指令需要被调整?这些指令的哪些部分要被调整?怎么调整?
事实上,在 ELF 文件中有一个重定位表(Reloaction Table)的结构专门用来保存这些与重定位相关的信息。它在 ELF 中往往是一个或多个段。如.rel.text, .rel.data,我们可以使用 objdump -r xx.o 来查看重定位表。每一个需要重定位的地方叫做一个重定位入口(Relocation Entry),入口的偏移量(Offset) 表示该入口在要被重定位的段中的位置。
对32位 Intel x86 系列的处理器来说,重定位表的结果也很简单:
1 | typedef struct |
| r_offset | 重定位入口的偏移。对于可重定位文件来说,这个值是该重定位入口所要修正的位置的第一个字节相对于段起始的偏移 |
| r_info | 重定位入口的类型和符号。低8位表示类型,高24位表示重定位入口的符号在符号表中的下标 |
符号解析
重定位过程中,每个重定位的入口都是对一个符号的引用,那么链接器需要对某个符号的引用进行重定位的时候,它就要确定这个符号的目标地址,这时链接器就会去查找所有输入目标文件的符号表组成的全局符号表,找到后进行重定位。
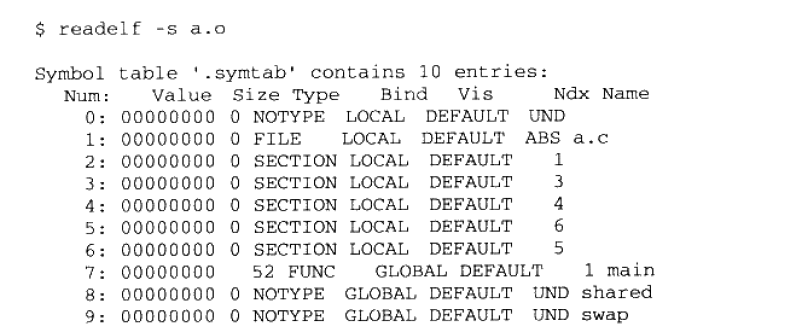
GLOBAL 类型的符号除了 main 定义在代码段外,其余都是 UND,即 undefined。当链接器扫描完所有的输入目标文件之后,所有这些定义的符号都应该可以在全局符号表中找到,否则链接器就报符号未定义的错误。
指令修正方式
| 宏定义 | 值 | 重定位修正方法 |
|---|---|---|
| R_386_32 | 1 | 绝对寻址修正 |
| R_386_PC32 | 2 | 相对寻址修正 |
-
绝对寻址修正:S + A ,相对寻址修正:S + A - P
- A = 保存在被修正位置的值
- P = 被修正的位置(相对于段开始的偏移量或者虚拟地址)
- S = 符号的实际地址,r_info 的高 24 位指定的实际地址
-
我们假设 main 函数的虚拟地址为 0x1000, swap 函数为 0x2000, shared 变量为 0x3000
- shared: S = 0x3000, A = 0x0000, result = 0x3000
- swap: S = 0x2000, A = 0xFFFFFFFC P = 0x1000 + 0x27(被修正位置的虚拟地址) result = 0xFD5
COMMON 块
- 如果弱符号定义在多个目标文件中,而它们的类型又不同,怎么办?变量类型对于链接器来说是透明的,它只知道一个符号的名字,并不知道类型是否是一致的。当我们定义的多个符号定义类型不一致是,主要分为三种情况:
- 两个或两个以上的强符号类型不一致 -> 非法
- 有一个强符号,其他都是弱符号,出现类型不一致
- 两个或两个以上弱符号不一致
- 为了处理后面两种问题,链接器都支持一种叫 COMMON 块的机制。即以最大的为准。
- COMMON 类型的规则主要是针对符号都是弱符号来说的,当有强符号时,最终和强符号一致。
C++ 相关问题
重复代码消除
C++ 编译器在很多时候会产生重复的代码,比如模板(Template),外部内联函数(Extern Inline Function)和虚函数表(Virtual Function Table)都可能在不同的编译单元里生成相同的代码。最简单的情况就拿模板来说,模板从本质上来讲很像宏,当模板在一个编译单元里被实例化时,它并不知道自己是否在别的编译单元也被实例化了。所以当一个模板在多个单元同时实例化相同的类型时,必然会产生重复的代码。
为了解决这个问题,一个比较有效的方法就是将每个模板的实例的代码都单独地存放在一个段里,每个段只包含一个模板实例。如一个模板函数 add<T>(),某个编译单元以 int 类型和 float 类型实例了该模板函数。那么该编译单元的目标文件中就包含了两个该模板实例的段。为了简单起见,我们假设这两个段的名字分别叫 .temp.add
这种做法被主流的编译器采用。GCC 把这种类似的需要在最终合并的段叫做 “Link Once”,它的做法是将这些段命名为 “.gnu.linkonce.name”, name 是该模板函数实例的修饰后名称。
函数级别链接
VISUAL C++ 提供了一个编译选项叫函数级别链接(Function-Level Linking),这种做法可以很大程度上减小输出文件的长度,减少空间浪费。但这个优化选项将所有的函数像模板函数一样单独保存到一个段里,用的时候就合并到输出文件,不用就废弃。这样会使编译更加慢,目标文件也会变大。 GCC 也有类似的编译选项。
全局构造和析构
Linux 下一般程序的入口是 “_start”, 这个函数是 Linux 系统库(Glibc)的一部分。这个函数就是程序的初始化部分的入口,程序初始化部分完成一系列初始化过程后,会调用 main 函数来执行程序的主体。在 main 执行完成以后,返回初始化部分,它进行一些清理工作,然后结束进程。
对于有些场合,程序的一些特定操作必须在 main 函数之前被执行,还有一些操作必须在 main 之后执行,如 C++ 全局对象的构造和析构。因此,ELF 定义了两种特殊的段:
- .init: 保存可执行指令,构成了进程的初始代码,有 Glibc 的初始化部分安排执行这个段中的代码
- .fini:保存进程终止代码指令,当 main 函数正常退出时,Glibc 会安排执行这个段中的代码。
C++ 和 ABI
如果要是两个编译器编译出来的目标文件能够相互链接,那么这两个目标文件必须满足下面这些条件:采用相同的目标文件的格式,拥有相同的符号修饰标准,变量的内存分布方式相同,函数的调用方式相同等等。我们把符号修饰标准,变量内存分布,函数调用方式这些和可执行代码二进制兼容性相关的内容称为 ABI(Application Binary Interface)
静态库链接
一个程序如何输入输出?最简单的方法是使用操作系统提供的应用程序编程接口(API),那程序是如何使用操作系统提供的 API?
一种语言的开发环境往往会附带有语言库(Language Library),这些库就是对操作系统的 API 的包装。如 printf 函数,在各个操作系统中,向终端输出字符串的 API 都不一样,Linux 下是一个 write 的系统调用,而 Win 下则是 WriteConsole 系统 API。
其实静态库可以看做是一组目标文件的集合,即很多目标文件经过压缩而形成的一个文件,我们可以使用 ar 工具来查看静态库包含了那些目标文件。
ar -t xxx.a
1 | ar -t libc.a |
可以使用ar -x xx.a 来将这些目标文件解压到当前目录
链接过程控制
整个链接过程有很多内容需要确定:使用哪些目标文件?使用哪些库文件?是否在最终可执行文件中保留调试信息?输出文件格式?还有考虑是否要导出某些符号以供调试器,程序本身或其他程序使用等。
链接控制脚本
链接器一般都提供多种方式控制整个链接过程,可以使用命令行参数,可以链接指令放到目标文件里,也可以使用链接控制脚本。当我们使用 ld 不指定脚本时会使用默认的链接脚本,一般在 “/usr/lib/dscripts/” 下,我们可以使用 -T 参数来指定自己的链接脚本。
书中的最小的程序咋也没法运行…
BFD 库
由于现代的硬件和软件平台种类繁多,它们之间千差万别。这些五花八门的软硬件导致每个平台都有其独特的目标文件格式。即使同一个格式如 ELF 也有很多的变种。种种差异导致编译器和链接器很难处理不同平台之间的目标文件。最好有一种统一的接口来处理这些不同格式之间的差异。
BFD(Binary File Descripor library)就是这样一个 GNU 项目,它就是希望通过一种统一接口的方式来处理不同的目标文件的格式。 BFD 这个项目本身是 binutils 项目中的一个子项目。 BFD 把目标文件抽象成一个统一的模型。比如在这个抽象的目标文件模型中,最开始有一个描述整个文件信息的"文件头",文件头后面是一系列的段,每个段都有属性,名字和内容。同时还定义抽象符号表,重定位表,字符串表等类似的概念。使得 BFD 库的程序只要通过抽象的目标文件模型就可以实现操作所有 BFD 支持的目标文件。
现在 GCC,链接器 ld,调试器 GDB 及 binutils 的其他工具都是通过 BFD 库来处理目标文件,而不是直接操作目标文件。这样做的最大的好处就是将编译器和链接器本身同具体的目标文件隔离开来,一旦我们需要支持一种新的目标文件格式,只需要在 BFD 中添加一种格式即可,而不需要修改编译器和链接器。