
程序员的自我修养—目标文件里有什么
- 2020.2.2 更新补充内容
迟到的更新
在开始这一章之前,先复习一下gcc的操作
复习
- -c
只编译,不链接成为可执行文件。编译器只是由输入的 .c 等源代码文件生成 .o 为后缀的目标文件,通常用于编译不包含主程序的子程序文件。 - -o output_filename
确定输出文件的名称为output_filename。同时这个名称不能和源文件同名。如果不给出这个选项,gcc就给出默认的可执行文件 a.out
- -g
产生符号调试工具(GNU的 gdb)所必要的符号信息。想要对源代码进行调试,就必须加入这个选项。 - -O
对程序进行优化编译、链接。采用这个选项,整个源代码会在编译、链接过程中进行优化处理,这样产生的可执行文件的执行效率可以提高。 - -O2
比 -O 更好的优化编译、链接。当然整个编译链接过程会更慢。 - -E
预编译后停下来,生成后缀为 .i 的预编译文件。 - -c
编译后停下来,生成后缀为 .o 的目标文件。 - -S
汇编后停下来,生成后缀为 .s 的汇编源文件。
整体来看的话:
第一步:进行预编译,使用 -E 参数
gcc -E test.c -o test.i
查看 test.i 文件中的内容,会发现 stdio.h 的内容确实都插到文件里去了,而其他应当被预处理的宏定义也都做了相应的处理。
第二步:将 test.i 编译为目标代码,使用 -c 参数
gcc -c test.c -o test.o
第三步:生成汇编源文件
gcc -S test.c -o test.s
第四步:将生成的目标文件链接成可执行文件
gcc test.o - o test
目标文件里有什么
目标文件的格式
现在PC平台流行的**可执行文件格式(Executable)**主要是Win下的PE(Portable Executable)和Linux下的ELF(Executable Linkable Format),它们都是COFF(Common File Format)格式的变种。而目标文件就是源代码编译后但未链接的中间文件。
不光是可执行文件按照可执行文件格式存储。动态链接库(DLL,Dynamic Linking Library)如Win下的.dll,Linux下的.so 文件也按照可执行文件格式存储。但静态链接库稍稍有些不同,它是把很多目标文件捆绑在一起形成一个文件,再加上一些索引,可以简单的理解为一个包含有很多的目标文件的文件包。
| ELF文件类型 | 说明 | 实例 |
|---|---|---|
| 可重定文件(Relocatable File) | 这类文件包含了代码和数据,可以被用来链接生成可执行文件或共享目标文件,静态链接库可以归在这一类 | Linux下的.o,Win下的.obj |
| 可执行文件(Executable File) | 直接的机器码,一般没扩展名 | /bin/bash文件,Win下的.exe |
| 共享目标文件(Shared Object File) | 这种文件包含了代码和数据,可以在两种情况下使用,一种是链接器可以使用这种文件和其他的可重定位文件和共享目标文件链接,产生新的目标文件。第二种是动态链接器可以将几个这种共享目标文件与可执行文件结合,作为进程映像的一部分 | Linux的.so,Win下的DLL |
| 核心转存储文件(Core Dump File) | 当进程意外终止时,系统可以将该进程的地址空间的内容及终止时的一些其他信息转储到核心转储文件 | Linux下的core dump |
使用file命令可以查看文件格式
1 | > vim foo.c |
发现一个神奇的东西/lib64/l,进到目录里看
1 | > cd /lib64 |
看到ld-linux-x86-64.so是我们想找到的共享的动态链接库,但ld-linux-x86-64.so.2又是什么呢?
ld-linux.so.2 是linux下的动态库加载器/链接器
当需要动态加载时,操作系统将控制权交给这个interpreter,用来定位和加载所有的动态库(注意> file foo给出的dynamically linked, interpreter /lib64/l)
还有一点值得留意,我们发现gcc foo.c -o foo生成了一个共享目标文件,经过查询得到了一定的了解
如果想要生成可执行文件,需要使用-no-pie指令来禁掉一个gcc的默认选项
Position-Independent-Executable是Binutils,glibc和gcc的一个功能,能用来创建介于共享库和通常可执行代码之间的代码–能像共享库一样可重分配地址的程序,这种程序必须连接到Scrt1.o。标准的可执行程序需要固定的地址,并且只有被装载到这个地址时,程序才能正确执行。PIE能使程序像共享库一样在主存任何位置装载,这需要将程序编译成位置无关,并链接为ELF共享对象。
引入PIE的原因是让程序能装载在随机的地址,通常情况下,内核都在固定的地址运行,如果能改用位置无关,那攻击者就很难借助系统中的可执行码实施攻击了。类似缓冲区溢出之类的攻击将无法实施。而且这种安全提升的代价很小
目标文件是什么样子
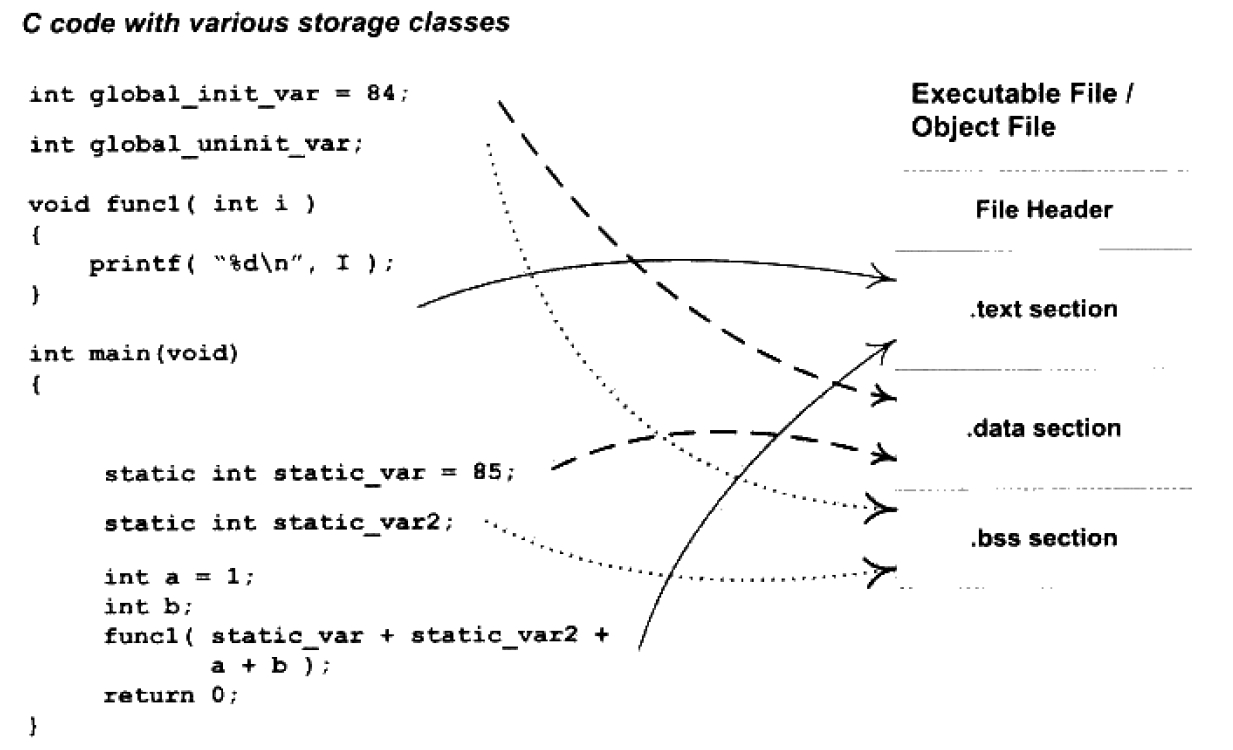
假设可执行文件(目标文件)的格式是ELF,从图来看,ELF文件的开头是一个“文件头”,它描述了一个文件是否可以执行,是静态链接还是动态以及入口地址,目标硬件,目标操作系统等信息。同时,文件头还包括一个段表(Section Table),段表其实就是一个描述文件中各个段的数组。段表描述了文件中各个段在文件中的偏移位置及段的属性等。
-
C语言编译后执行语句都编译成机器代码,保存在.text段
-
已经初始化的全局变量和局部静态变量都保存在.data段
-
未初始化的全局变量和局部静态变量一般放在.bss段里,这个段只是为未初始化的全局变量和局部变量预留位置而已,它并没有内容,所以在文件里不占据空间
未初始化的全局变量和局部静态变量默认值都是0,本来都可以放在.data段里,但因为都是0,所以在.data段分配空间并且存0没有意义,但运行时还要占空间,所以放在了.bss段
总的来说,程序的源代码被编译以后主要分成两种段:程序指令和程序数据。代码段属于程序指令,而数据段和.bss段属于程序的数据,为什么要这么麻烦呢?
- 程序被装载后,数据和指令分别被映射到两个虚存区域。由于数据区对于进程来说可读可写,而指令区对于进程来说只可读,这样划分段便于分权
- 对现代CPU的缓存(Cache)有益,现代的CPU一般都设计成数据缓存和指令缓存分离,分离段可以提高缓存的命中率
- 和操作系统节省内存空间相关:当系统中运行着多个该程序的副本时,他们的指令一样,所以内存中只用保存一份该程序的指令部分(只读的),当然对于只读数据也是这样的,如程序里的图标,文本,图片也是可以共享的。当然,进程的数据私有。
挖掘.o文件
1 | int printf(const char* format, ...); |
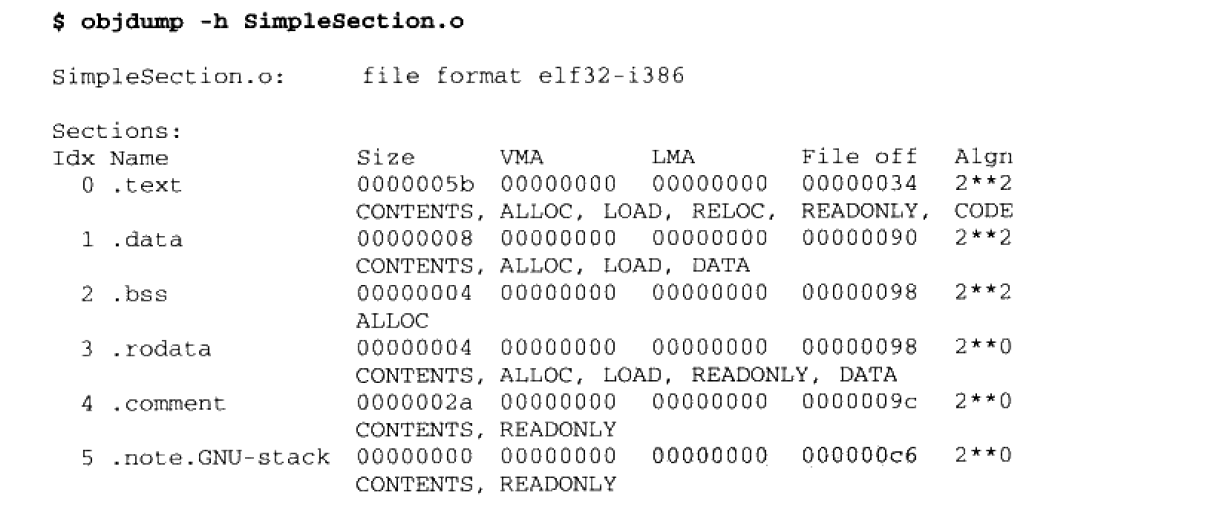
出了最基本的代码段,数据段和 BSS 段以外,还有 3 个段分别是只读数据段(.rodata),注释信息段(.comment),堆栈提示段(.note.GNU-stack),我们暂时不研究这三个段,把重点放在属性上:属性有长度(size),位置(file offset),每个段的第二行中的 “CONTENTS” 表示该段在文件中存在。 BSS 段就没有这个属性。 还有一个大小为 0 的堆栈提示段,也同样暂时忽略,这样我们就大致得到了文件的结构(可能会由于编译器版本和机器平台导致大小不太一致)
|–|–|
|elf header|0x0~0x34|
|.text|0x34~0x90(这里应该是对齐了边界)|
|.data|0x90~0x98|
|.rodata|0x98~0x9c|
|.comment|0x9c~0xc6|
|other data|…|
代码段
- 使用
objdump -s -d xxx来查看16进制的段内容和反汇编
数据段和只读数据段
- .data 段保存了初始化了的全局静态变量和局部静态变量。分别是 static_var, global_init_var 共 8 字节。
- 在调用 printf 时,格式化字符是以只读存入的,故被放入了 .rodata 段,
%d\n再加上'\0'是 4 字节。
rodata 段在语义上支持了 const 关键字,也为操作系统处理只读提供了方便,保证程序的安全
BSS 段
- 存放为初始化的全局变量和局部静态变量, .bss 段为他们预留了空间,但 global_uninit_var, static_var2 应为 8 字节,实际只存储了 4 字节,这是因为符号表(Symbol Table),实际上只有 static_var2 被放在了 bss 段,而 global_uninit_var 只是一个未定义的 COMMON 符号。而且这会因不同编译器的实现而不同,有些编译器会将全局未初始化的变量存在 bss 段,而有些仅仅只会预留一个未定义的全局变量符号
其他段
| 段名 | 说明 |
|---|---|
| .rodata1 | 和.rodata一样 |
| .comment | 存放编译器的版本信息 |
| .debug | 存放调试信息 |
| .dynamic | 动态链接信息 |
| .hash | 符号哈希表 |
| .line | 调试时的行号表,即源代码行号与编译后指令的对应表 |
| .note | 额外的编译器信息,如公司名,发布版本号 |
| .strtab | String Table 字符串表,用于存放ELF中用到的各种字符串 |
| .symtab | Symbol Table 符号表 |
| .shstrtab | Section String Table 段名表 |
| .plt & .got | 动态链接的跳转表和全局入口表 |
| .init & .fini | 程序初始化与终结代码段 |
- 当然应用程序也可以使用一些非系统保留的名字作为段名,如加入一个 music 段来存放一些音乐的信息。这样这个文件只有你自己写的读取程序可以解析。但注意应用程序定义的段名不能用. 前缀。
- 还有些段名是历史遗留问题,不用理会,如 .sdata, .confict, …
补充
-
如何在 64 位的电脑编译 32 位的程序呢,如果直接使用
gcc -c得到的是 elf64-x86-64 的 64 位格式的文件,这时我们需要gcc -m32 -c这样得到的就是 elf32-i386 格式的文件 -
但是这个文件我们查看结构和书上的并不完全一样
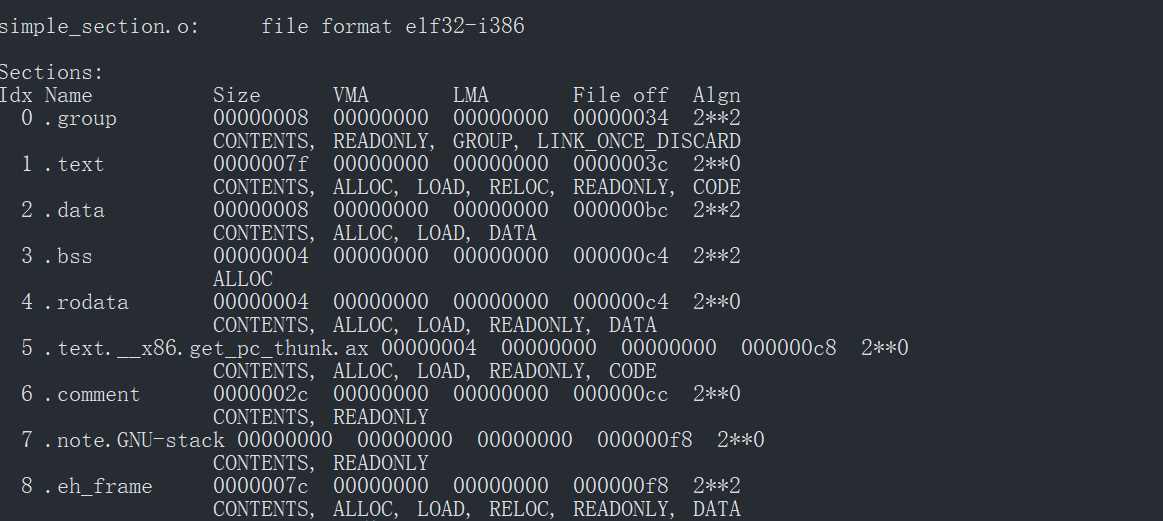
- .group 段: ???
- .eh_frame 段: 调试信息段
ELF 文件结构描述
ELF 目标文件格式最前部是 ELF 文件头(ELF Header), 其包含了描述整个文件的基本属性,比如 ELF 文件版本,目标机器型号,程序入口地址等。ELF 文件中与段有关的重要结构就是段表(Section Header Table),该表描述了 ELF 文件包含的所有段的信息,比如每个段的段名,段长度,文件中的偏移位置,读写权限以及其他属性。
文件头
readelf -h xx 查看 ELF 文件头
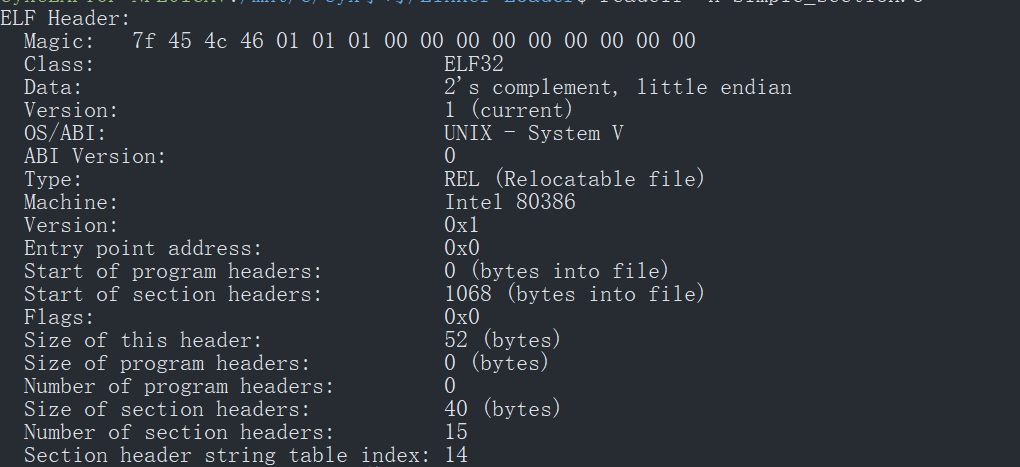
ELF 文件头结构及相关常数被定义在 “/usr/include/elf.h” 里,因为 ELF 文件在各种平台下都通用,ELF 文件有 32 位版本和 64 位版本。内容一样但是有些成员的大小不一样。 elf.h 中使用 typedef 定义了一套自己的变量,ELF 详细的定义可以在 ELF 标准文档里找到。
1 | typedef struct |
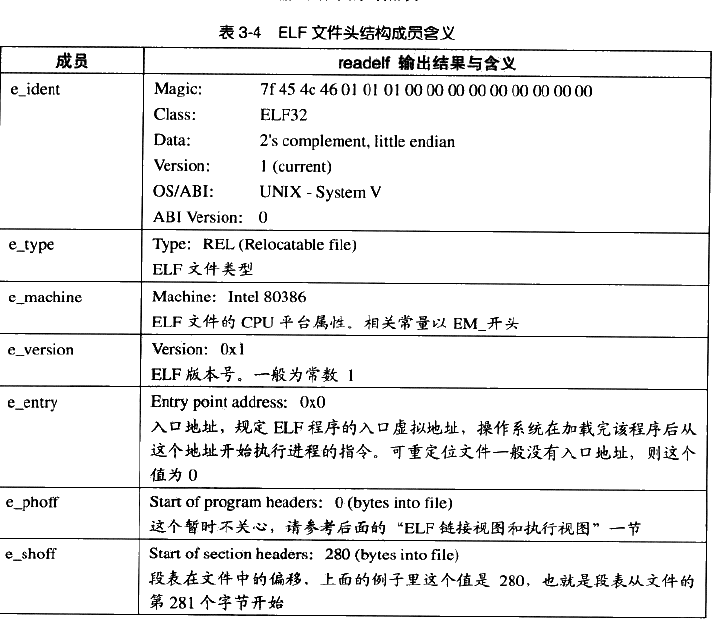

ELF 魔数
“Magic”,这 16 个字节被 ELF 标准规定用来标识 ELF 文件的平台属性,比如这个 ELF 的字长(32/64),字节序,ELF 文件版本。

-
最开始的 4 个字节是所有 ELF 文件必须相同的标识码,分别为 0x7F,0x45,0x4c,0x46,第一个字节对应的 ASCII 字符里的 DEL 控制符,后面三个是 ELF 这三个字母的 ASCII 码。魔数用来确认文件的类型,操作系统在加载可执行文件时会确认魔数是否正确,否则拒绝加载。
-
接下来的一个字节用来标识 ELF 的文件类,0x01 表示为32位, 0x02 表示为64位,第6个字是字节序,规定大端还是小端。第7个字节规定 ELF 文件的主版本号,一般是1。 ELF 对后面的9个字节没有标准,一般是0,有些平台会使用这9个字节作为扩展标志。
文件类型
| 常量 | 值 | 含义 |
|---|---|---|
| ET_REL | 1 | 可重定位文件,一般为.o |
| ET_EXEC | 2 | 可执行文件 |
| ET_DYN | 3 | 共享目标文件,一般为.so |
段表
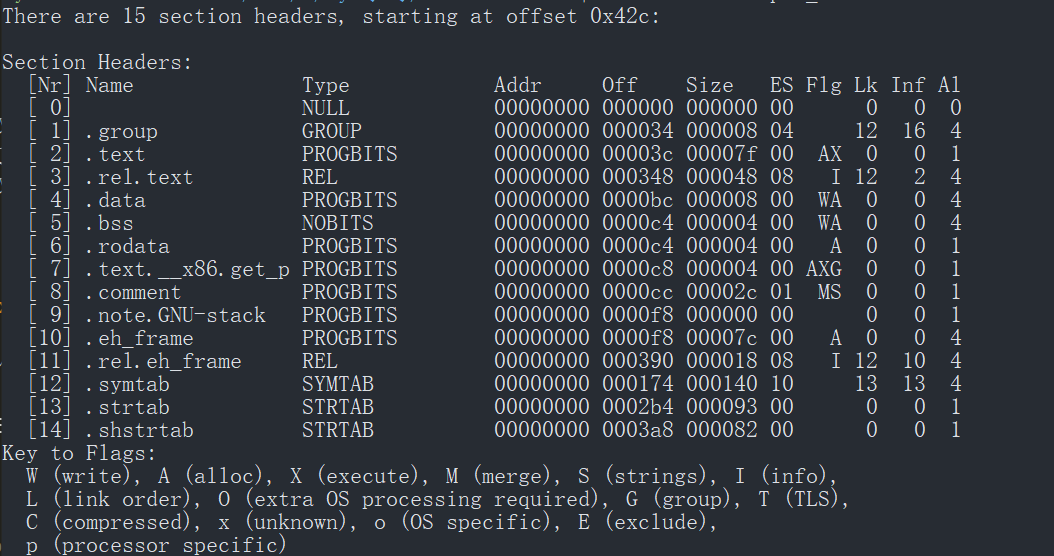
使用 readelf -S xxxx.o 来查看段表,它是一个以 “Elf32_Shdr” 结构体为元素的数组。其被定义在 elf.h 中
段表是 ELF 中除了文件头以外的最重要的结构,它描述了 ELF 各个段的信息,比如说段名,段长度,在文件中的偏移,读写权限以及段的其他属性。也就是说,ELF 文件的段结构就是由段表决定的,编译器,链接器和装载器都是依赖段表来定位和访问各个段的属性的。段表在文件中的偏移位置由 ELF 文件头中的 “e_shoff” 成员决定。
1 | /* Type for a 16-bit quantity. */ |
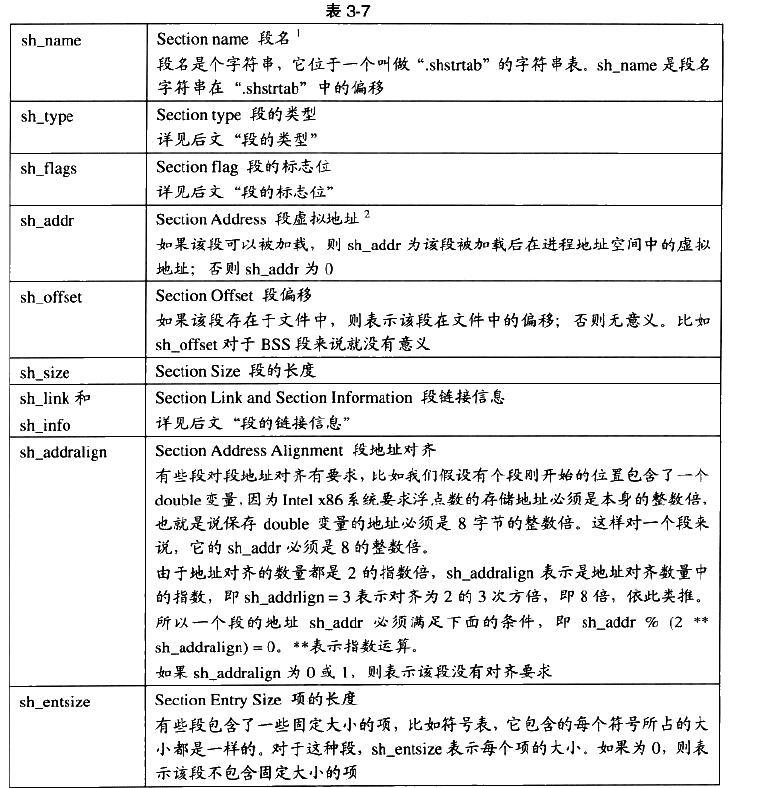
- 虚拟地址涉及一些映像文件的加载的概念,会在后面解释说明
- 段的名称对于编译器,链接器是有意义的,但对于操作系统没有实质的意义,对于操作系统来说,一个段该如何处理取决于它的属性和权限,即由段的类型和标志这两个成员决定。
段的类型(sh_type)
| 常量 | 值 | 含义 |
|---|---|---|
| SHT_NULL | 0 | 无效段 |
| SHT_PROGBITS | 1 | 程序段,代码段,数据段都是这种类型 |
| SHT_SYMTAB | 2 | 表示该段的内容为符号表 |
| SHT_STRTAB | 3 | 表示该段的内容为字符表 |
| SHT_RELA | 4 | 重定位表,该段包含重定位的信息 |
| SHT_HASH | 5 | 符号的哈希表 |
| SHT_DYNAMC | 6 | 动态链接信息 |
| SHT_NOTE | 7 | 提示性信息 |
| SHT_NOBITS | 8 | 表示该段在文件中没有内容,如.bss |
| SHT_REL | 9 | 该段包含重定位信息,会在后面说到 |
| SHT_SHLIB | 10 | 保留 |
| SHT_DNYSYM | 11 | 动态链接的符号表 |
段的标志位(sh_flag)
表示该段在进程虚拟地址空间中的属性,比如是否可写,是否可执行
|常量|值|含义|
|SHF_WRITE|1|表示该段在进程空间中可写|
|SHF_ALLOC|2|表示该段在进程空间需要分配空间,像代码段,数据段,.bss段都会有|
|SHF_EXECINSTR|4|表示该段在进程空间可以被执行,一般指代码|
段的链接信息(sh_link, sh_info)
如果段的类型与链接相关,比如重定位表,符号表,那么这两个成员所包含的含义为:
- SHT_DYNAMIC: link: 该段所使用的字符串表在段表中的下标,info: 0
- SHT_HASH: link: … 符号表 …, info: 0
- SHT_REL & SHT_RELA: link: 使用的符号在段表中的下标,info: 重定位表作用的段在段表中的下标
- SHT_SYMTAB & SHT_DYNSYM: link & info: 操作系统相关
重定位表
对于每个需要重定位的代码段或数据段都会有一个对应的相应的重定位表
- .rel.text 就是针对 .text 的重定位表,我们也可以通过 info 来看其对应的重定位的段
字符串表
ELF 文件中用到了很多字符串,比如段名,变量名等,因为字符串的长度往往不定,所以就集中起来然后用在表中的偏移量来引用字符串,偏移量表示头,'\0’表示结尾
一般字符串表在 ELF 中也以段的形式保存,常见的段名为 .strtab 或 .shstrtab 前一个存普通的字符串,后一个存储段表用到的字符串,如 sh_name
我们回头看 ELF 文件头里的 “e_shstrndx”(Section header string table index)的缩写,其表示 .shstrtab 在段表(数组)中的下标,即段表字符串表在段表中的下标。这样我们分析 ELF 文件头就可以得到段表,而通过段表里索引的段字符表值以及段字符表的位置,我们就可以解析整个 ELF 文件了。
程序员的自我修养—目标文件里有什么