
汇编语言语法-1
汇编语言
前言
声明:
- 个人学习的是基于x86和Intel64处理器的汇编语言编程与架构
- 主要分两部分,语法和实验/实操
- 语法部分学习书籍:《汇编语言——基于x86处理器》(机械工业出版社)(对,就是那一套外国书里的一本),我尝试采用问答的方式写这一系列的博客,问题选自书上的问题
- 实验部分为课后习题或者是有意思的东东
汇编语言基础
基本语言元素
Q: 使用数值-35,按照MASM语法,写出10进制,16进制,8进制,2进制格式
K:MASM(Microsoft宏汇编器,Microsoft Macro Assembler)规则下,整数常量由一个可选前置符,数字和基数构成
[{ + | - }] digits [ radix ]
| 后缀 | 基数 |
|---|---|
| h | 十六进制 |
| q//o | 八进制 |
| d | 十进制 |
| b | 二进制 |
当进行有符号的十进制向别的进制转换时,先取绝对值,将绝对值转成对应进制,再取补码。
如题中-35转2进制:
35 -> 00100011(不足高位补0) -> 11011101(补码)
A:-35d; DDh; 335o; 11011101b
Q:A5h是一个有效的十六进制常量吗
A:不是,以字母为开头的十六进制数必须加一个前置0,防止汇编器解释称标识符
Q:安照MASM语法写出实数-62000的实数常量
K:(就和C很像)
[ sign ] interger.[ interger ][ exponent ]
A: -6.2E+04
Q: 字符常量是什么,字符串常量必须包含在单引号中吗?
A:字符常量是指用单引号或双括号包含的一个字符,汇编语言在内存中保存该字符的ASCII码数值;字符串常量允许被包含单/双引号中,其在内存中保存形式为整数字节数值序列
Q:保留字可以用作助记符,属性,运算符,预定义符号和______
A:伪指令
K:
- 标识符,可以理解为变量,用于标识变量,常量,子程序,代码标签。最多247个字符,不区分大小写
- 伪指令,命令,由汇编器识别执行
- 定义段(segment),即定义程序区段,如.data数据段, .code程序段
- 指令助记符,标记指令的短单词
| 助记符 | 说明 |
|---|---|
| MOV | 传值 |
| ADD | 数值相加 |
| SUB | 数值相减 |
| MUL | 数值相乘 |
| JMP | 跳转到一个新位置 |
| CALL | 调用子程序 |
补充:
-
注释,单行以;开头, 块,COMMENT 和一个用户定义的符号,汇编器会忽略其代码直到和用户定义的符号相同的符号出现时
如:
COMMENT!
2333333
! -
NOP,空操作指令
第一个汇编程序:整数加减
1 | ; AddTwo.asm - adds two 32-bit integers. |
目前不用完全看懂
- .386表明这是32位程序,可以访问32位的寄存器和地址
- .flat指定内存模式
- stdcall确定了子程序调用规范
- .stack 4096 运行时堆栈保留了4096字节存储空间
- Exit行,声明ExitProcess原型,原型包括函数名,PROTO关键字,一个逗号,一个输入参数表
- end伪指令标记一个程序的结束,并要引入程序入口
- main 标识程序入口,即程序要执行的第一条指令的位置
- endp用于标识一个进程的结束,这里为main的结束
汇编,链接与运行
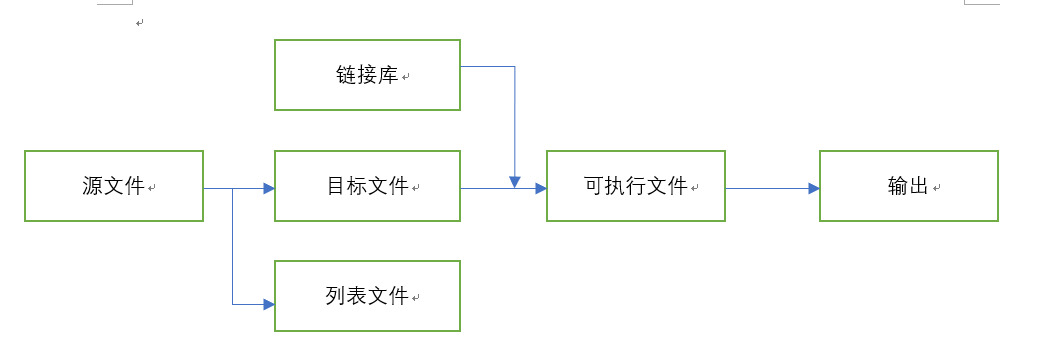
源文件-(汇编器-目标文件-(链接器)-可执行文件-(OS加载器)-结果
Q:汇编器生成什么类型的文件
A:汇编器读取源文件,目标文件,即对程序的机器语言翻译。或者它也会生成列表文件
Q:链接器从链接库中抽取已汇编的程序,并将其插入到可执行程序中?
A:错,链接器读取并检查项目目标文件,检查是否有对链接库的调用,链接器从链接库里复制任何被请求的过程,将它们与目标文件组合生成可执行文件
Q:操作系统的那一部分来读取执行程序?
A:操作系统加载程序可以将可执行文件读入内存,并使cpu分支到该程序的起始地址,然后执行程序
定义数据
- BYTE和SBYTE定义8位变量
- WORD和SWORD定义16位变量
- DWORD和SDWORD定义32位变量
- QWORD和TBYTE分别定义8字节和10字节的变量
- REAL4,REAL8,REAL10分别定义4字节,8字节,10字节变量
Q:为一个16位有符号整数创建未初始化数据声明
K:问号(?)初始值使得变量未初始化,这意味着运行时分配数值
A:var1 SWORD ?
Q:为一个8位无符号整数创建未初始化数据声明
K:BYTE和SBYTE由于是8位,可以表示字符常量,如var1 BYTE ‘A’
但在定义字符串时,需要注意,需要空字节(0)作为结尾
如: greeting BYTE “Hello World”,0,
也可以这样:
greeting BYTE “Welcome”,0dh,0ah
BYTE “Hello World”,0
ps:若同一数据定义多个初始值,那么他们的位置只指出偏移量,在内存中相连
如 list BYTE 10,20,30,40
则偏移量为0000, 0001, 0002, 0003,这样是由于x86处理器内存按小端(little-endian)顺序,即从低到高存放检索数据
A:var1 BYTE ?
Q:假设有数值456789AB,按小端序列列出其字节内容
A:从小到大,0000 AB;0001 89;0002 67; 0003 45
##符号常量
Q:使用等号伪指令定义一个符号常量,使其包含Backspace键的ASCII码(08h)
K:很好理解,=就是把一个符号和一个整数表达式关联起来
A:backSpace = 08h
Q:
(1)编写一条语句使汇编器计算下列数组的字节数,并将结果赋给符号常量ArraySize
myArray WORD 20 DUP(?)
(2)编写一条语句使汇编器计算下列数组元素的个数,并将结果赋给符号常量ArraySize
myArray DWORD 20 DUP(?)
K:
- DUP用于给多个数据项复制,如
BYTE 20 DUP(?) ;20个字节,无初始化
BYTE 4 DUP(“STACK”) ;20个字节,4个字符串,每个都是“STACK” - 我们使用 $ 作为当前地址的计数器,
- $ - array就能得到语句偏移量,即数组字节数,而要计算数组元素,需要用字节数除以每个元素的大小(字数组WORD(每个2字节,16位),双字数组DWORD(每个4字节,32位))
注意下面情况:
list BYTE 1,2,3,4
var BYTE 20 DUP(?)
size = ($ - list)
size最终为24,别忘了存储地址是连续的,中间插入了20个BYTE
A:
1)ArraySize = $-myArray
2)ArraySize = ($-myArray)/2
Q:使用TEXTEQU将下面代码行赋值给setupESI
mov esi, OFFSET myArray
K:TEXTEQU用于创建文本宏(text macro)分三种情况:
name TEXTEQU
name TEXTEQU textmacro ;分配已有的文本宏
name TEXTEQU %constExpr ;分配整数常量表达式(注意有个%号)
A:setupESI = <mov esi, OFFSET myArray>
写在后面
- 这章编程题太简单了,没啥东西值得放上来,就去掉对应实验的博客了
- 这么简单的一章看了好几天,以后要加快速度了
- 配置环境参考:参考博客
ps:配置生成列表文件:
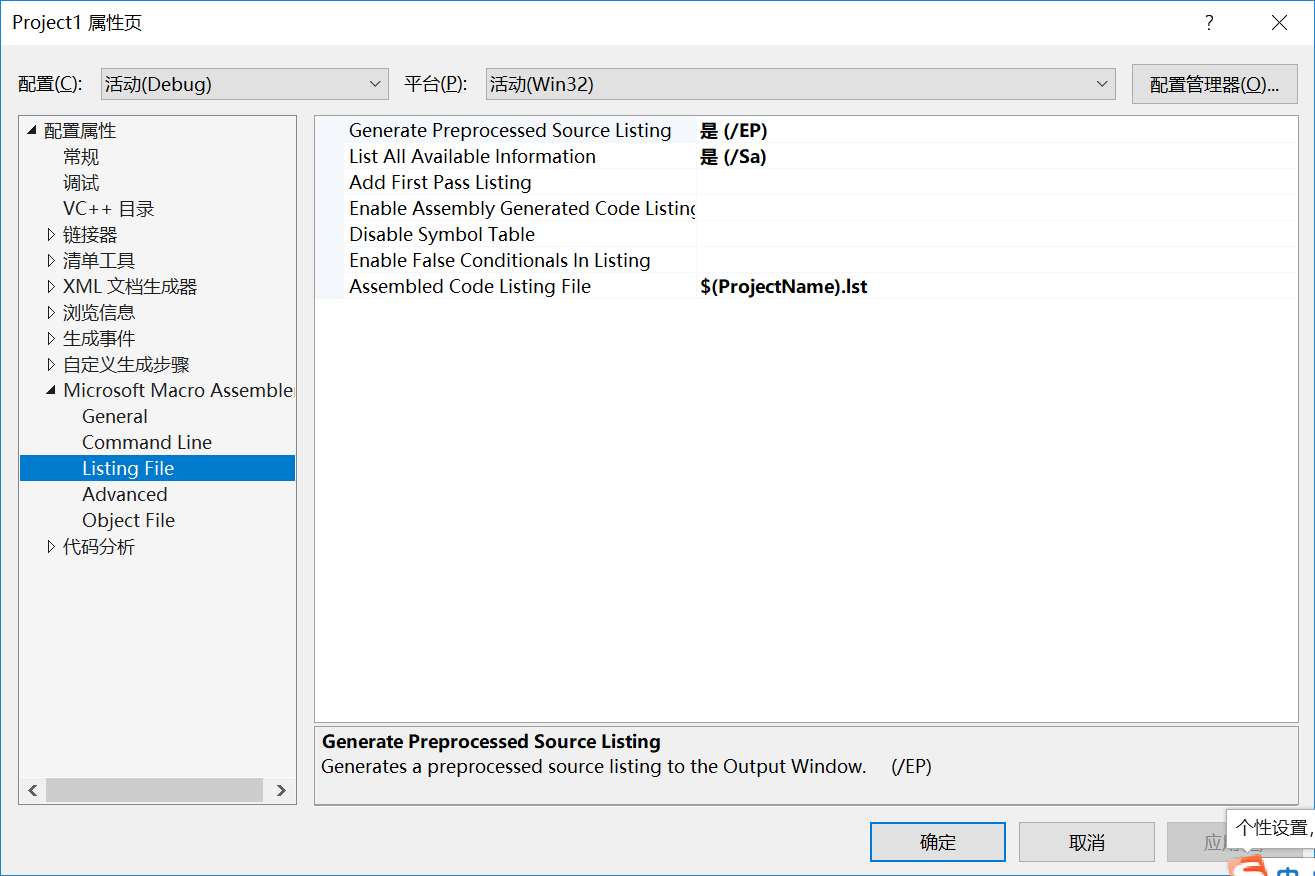
- 两个$之间 就可能被转为数学表达式